0
| 本文作者: AI研习社 | 2020-03-09 15:40 |

多轨迹预测研究
针对VI-ReID的分层跨模态行人在识别
3DMM 人脸模型:从过去到现在到未来
一种基于U-Net的生成性对抗网络判别器
用于图像描述的交叉模态信息的探索和蒸馏
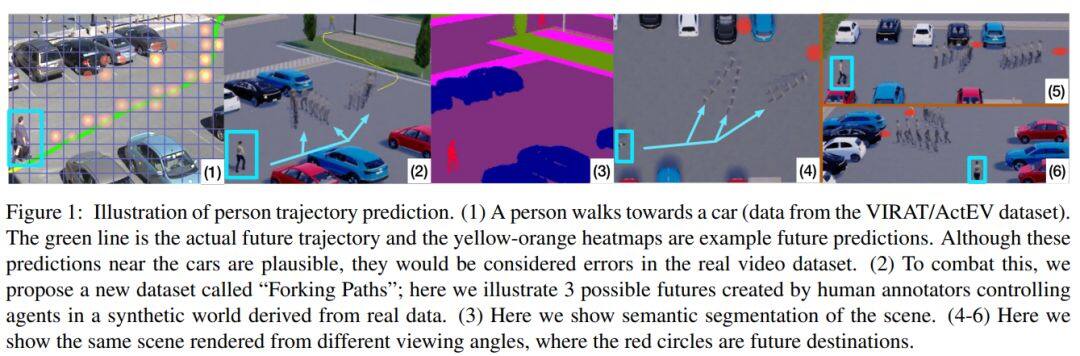
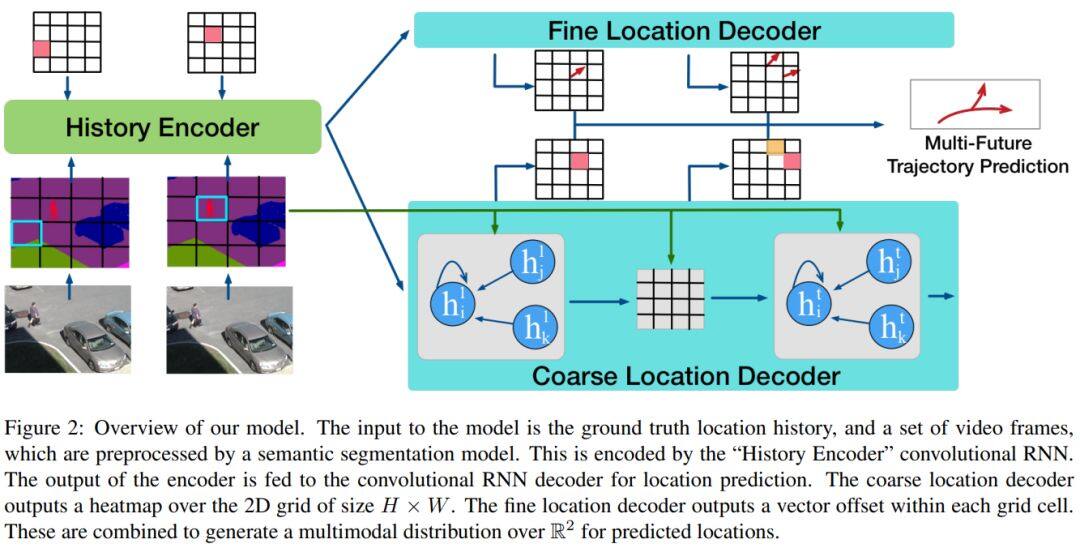
论文名称:The Garden of Forking Paths: Towards Multi-Future Trajectory Predictio
作者:Junwei Liang
发表时间:2020/2/1
论文链接:https://paper.yanxishe.com/review/13151?from=leiphonecolumn_paperreview0309
推荐原因
研究意义:
轨迹预测问题是目前AI方向研究的一个热点问题。基于此,本文利用多种不同轨迹类型研究了如何高效准确的预测出路径的可能分布,从而有助于未来在多目标预测方面的研究和应用。
创新点:
1、创建了一个基于我们现实世界中轨迹数据的3D模拟器数据集;
2、作者提出了一种新的模型,记为Multiverse,该模型可以准确地用于多轨迹预测。
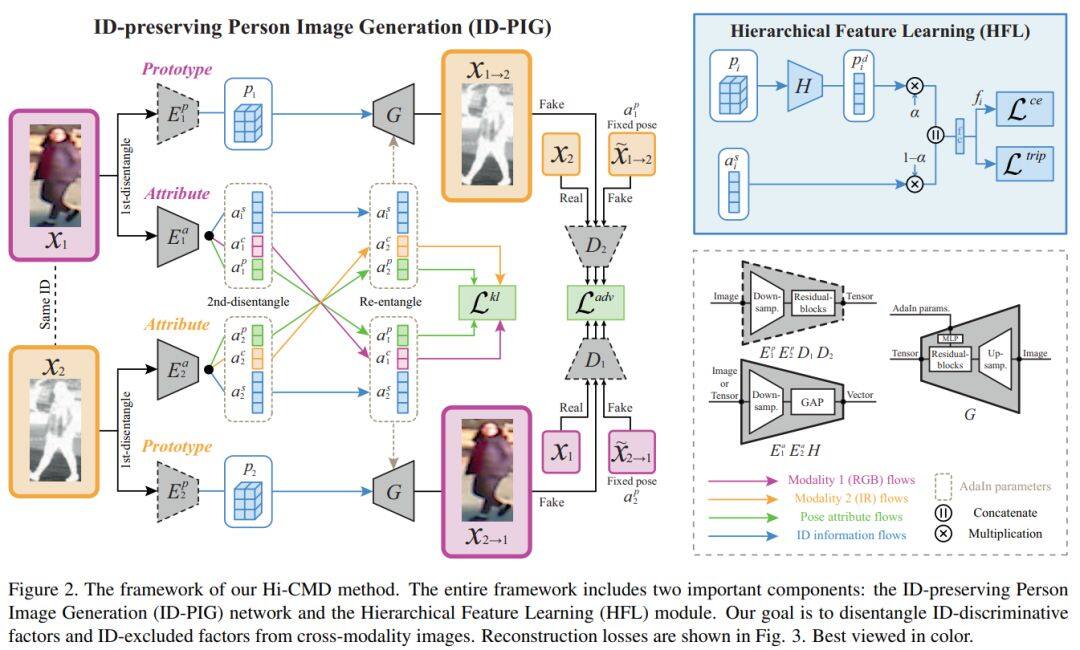
论文名称:Hi-CMD:HierarchicalCross-ModalityDisentanglementforVisible-Infrared PersonRe-Identification
作者:Seokeon Choi
发表时间:2020/2/1
论文链接:https://paper.yanxishe.com/review/13150?from=leiphonecolumn_paperreview0309
推荐原因
研究意义:通过对夜间视频的监控进行跨模态行人识别是当下ReID方向的一个的难点,目前已经受到学术界的广泛关注。在此背景下,作者提出了一种分层跨模态行人识别(Hi-CMD)方法。为了实现该方法,作者引入了ID-preserving图像的生成网络和层次特征学习模块,通过这种网络结构可有效的解决行人在不同姿势和照明条件下进行ReID任务。
文章的创新点
1、提出了种一种新颖的VI-ReID行人跨模态识别方法:Hi-CMD,与传统的模型方法相比,该模型通过区分ID-discriminative和可见红外图像中的ID-excluded两种因素,有效地减少了跨模态和模态内的差异。
2、利用ID-PIG网络,避免可能因训练数据不足而带来的问题。

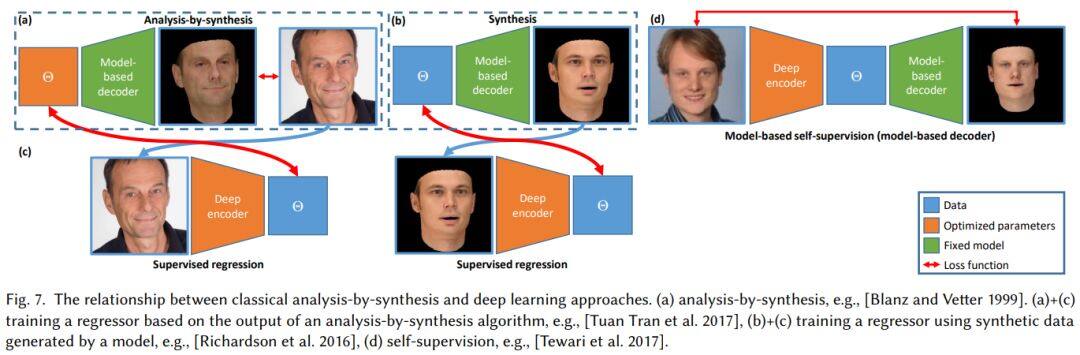
论文名称:3D Morphable Face Models -- Past, Present and Future
作者:Bernhard Egger / William A. P. Smith / Ayush Tewari / Stefanie Wuhrer / Michael Zollhoefer / Thabo Beeler / Florian Bernard / Timo Bolkart / Adam Kortylewski / Sami Romdhani / Christian Theobalt / Volker Blanz / Thomas Vetter
发表时间:2019/9/3
论文链接:https://paper.yanxishe.com/review/12956?from=leiphonecolumn_paperreview0309
推荐原因
文章详细介绍了 3DMM 人脸模型自20多年前提出至今以来的发展,是一篇非常全面非常优秀的综述文章,作者都是由该领域的前沿学者。
虽然已经提出有20多年,但 3DMM 模型的构建和应用,如捕捉、建模、图像合成和分析等等,仍然存在众多挑战,是一个非常活跃的研究主题,文章回顾了这些领域中的最新技术,在最后进一步进行了展望,提出了一些挑战,为未来的研究提供了一些方向,并强调了当前和未来的一些应用。
强烈建议相关专业学生和老师仔细研读,是一个不可多得的 3DMM 人脸模型的综述文章。

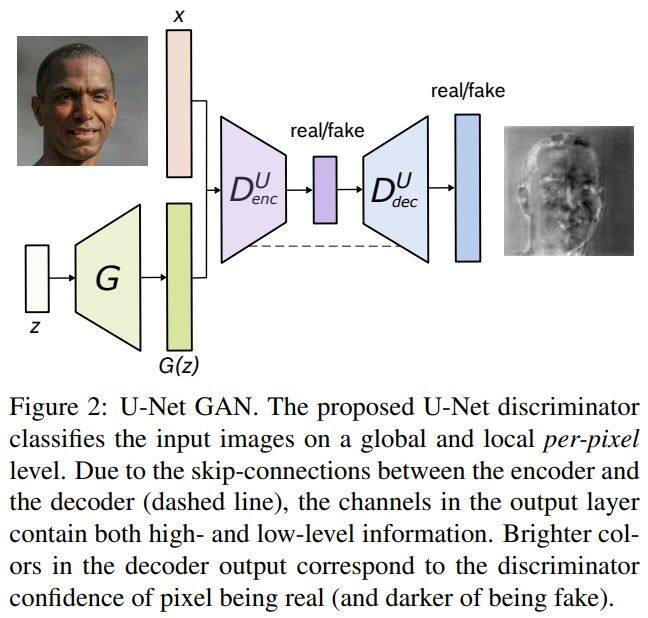
论文名称:A U-Net Based Discriminator for Generative Adversarial Networks
作者:Schönfeld Edgar /Schiele Bernt /Khoreva Anna
发表时间:2020/2/28
论文链接:https://paper.yanxishe.com/review/12959?from=leiphonecolumn_paperreview0309
推荐原因
这篇论文被CVPR 2020接收,提出了一种基于U-Net的判别器架构,在保持合成图像的全局一致性的同时,向生成器提供详细的每像素反馈。在判别器的每像素响应支持下,这篇论文进一步提出一种基于CutMix数据增强的逐像素一致性正则化技术,鼓励U-Net判别器更多关注真实图像与伪图像之间的语义和结构变化,不仅改善了U-Net判别器的训练,还提高了生成样本的质量。新判别器在标准分布和图像质量指标方面改进了现有技术,使生成器能够合成具有变化结构、外观和详细程度的图像,并保持全局和局部真实感。与BigGAN基线模型相比,所提方法在FFHQ、CelebA和COCO-Animals数据集上平均提高了2.7个FID点。

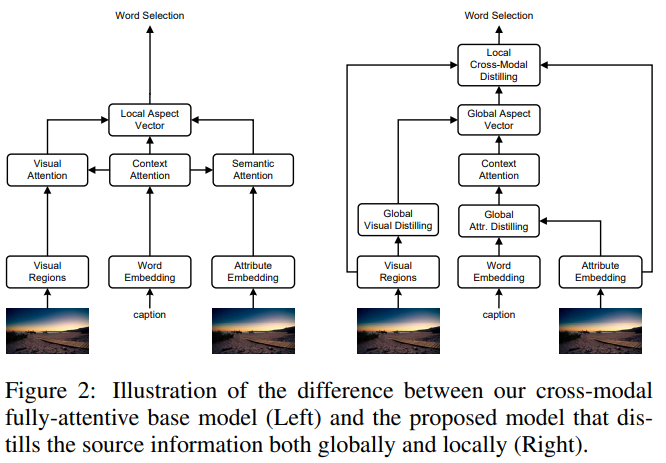
论文名称:Exploring and Distilling Cross-Modal Information for Image Captioning
作者:Liu Fenglin /Ren Xuancheng /Liu Yuanxin /Lei Kai /Sun Xu
发表时间:2020/2/28
论文链接:https://paper.yanxishe.com/review/12958?from=leiphonecolumn_paperreview0309
推荐原因
这篇论文要解决的是图像描述任务。
这篇论文认为图像理解需要相关区域的视觉注意力信息和对应感兴趣的属性的语义注意力信息。为进行有效的注意力捕获,这篇论文从交互模态的角度探索图像描述任务,并提出全局局部信息探索与蒸馏方法,同时以视觉的和语言的方式探索并提取原始信息。通过提取显著区域群组以及属性的搭配信息,新方法在全局参考基于字幕上下文的图像空间和关系表示,在局部提取细粒度区域和属性以进行单词选择。这篇论文所提的全注意力模型在离线COCO评估中获得129.3的CIDEr评分,在准确性、速度和参数量方面均具有优势。

为了更好地服务广大 AI 青年,AI 研习社正式推出全新「论文」版块,希望以论文作为聚合 AI 学生青年的「兴趣点」,通过论文整理推荐、点评解读、代码复现。致力成为国内外前沿研究成果学习讨论和发表的聚集地,也让优秀科研得到更为广泛的传播和认可。
我们希望热爱学术的你,可以加入我们的论文作者团队。
加入论文作者团队你可以获得
1.署着你名字的文章,将你打造成最耀眼的学术明星
2.丰厚的稿酬
3.AI 名企内推、大会门票福利、独家周边纪念品等等等。
加入论文作者团队你需要:
1.将你喜欢的论文推荐给广大的研习社社友
2.撰写论文解读
如果你已经准备好加入 AI 研习社的论文兼职作者团队,可以添加运营小姐姐的微信(ID:julylihuaijiang),备注“论文兼职作者”

雷锋网雷锋网雷锋网
相关文章:
今日 Paper | 4D关联图;通用表征学习;元转移学习;无偏场景图生成等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

