雷锋网按:本文原作者MagicBubble,原载于知乎专栏人工智障的深度瞎学之路。雷锋网已获得作者授权。
利用一个暑假的时间,做了研究生生涯中的第一个正式比赛,最终排名第二,有些小遗憾,但收获更多的是成长和经验。我们之前没有参加过机器学习和文本相关的比赛,只是学过一些理论基础知识,没有付诸过实践,看过的几篇论文也多亏前辈的分享(一个是用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践,另一个是 brightmart 的 text_classification,里面用 Keras 实现了很多文本分类的模型)。这些为我们的入门打下了良好的基础,在比赛过程中也是反复研读和实践,在此感谢两位前辈的无私分享。
先放一波链接:
下面对在这次比赛中用到的方法和收获的经验,做一个简单的总结和分享。
用单模型探索数据的极限
1. 任务
典型的文本多标签分类问题,根据用户在知乎上发布的问题标题及描述,判断它属于哪几个话题
训练数据给出了 300 万问题及其话题的绑定关系,话题标签共有 1999 个,有父子关系,构成有向无环图
要求对未标注的数据预测其最有可能绑定的 Top5 话题标签
评测采用准确率与召回率的调和平均,准确率的计算按照位置加权,越靠前的分数越高(具体见评测方案)
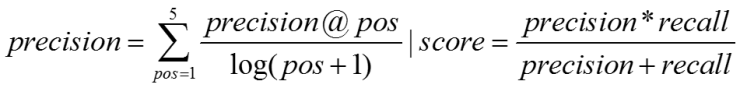
2. 数据
比赛提供的数据是 300 万问题和话题的标题(下称 title)及描述(下称 desc),分别有对应的字序列(下称 char)和词序列(下称 word),全部是以 id 的形式给出。这意味着我们是看不到原始文本的,所以对于 badcase 的分析也很困难,但好在其数据量够大(2 亿多词,4 亿多字),还是可以用深度学习来做。知乎官方也提供了训练好的 embedding(维度 256),字级别和词级别的都有,但是是分开训练,不属于同一个语义向量空间。

坊间常说:数据和特征决定了机器学习的上限,而模型和算法知识逼近这个上限而已。对于深度学习,因为不存在特征工程,所以数据处理就至关重要了。而良好且合理的数据处理离不开系统详细的数据分析,要知道数据是什么样,数据怎么分布,才能更好地选择模型和训练方式。
2.1 数据分析
这里主要是对问题的 title 和 desc 做长度分析,更为详细的分析见数据分析
首先是问题 title 的字词长度分布:

其次是问题 desc 的字词长度分布:

2.2 预处理
随机 shuffle 后以 9:1 的比例划分线下验证集和训练集,防止数据周期的影响
对于 embedding 矩阵中未出现的词,添加,并用 - 0.25~0.25 初始化,千万不能扔掉,这样会破坏前后的语义关系
对于 title 和 desc,分别根据其平均长度 * 2,做截断和补齐至长度一致,便于 batch 输入网络训练

3. 模型
参照 brightmart 的 github 开源,我们尝试了前 5 种模型,分别是 FastText、TextCNN、TextRNN、RCNN、HAN
其中,HAN 的原始论文中用的是词和句子两层 Attention,而数据中是看不出句子的,所以这个方法我只用了一层 word,效果不好。而 RCNN 因为同时用到了 RNN 和 CNN 的思想,所以整个网络的训练时间很长,且其效果与单独的 RNN 和 CNN 差不多,因此后期没有使用此模型。最终用到的模型有:

3.1 单模型 Score
因为没有花很多时间在单模型调参训练上,所以最终单 Model 的分数普遍偏低,约比别的队伍低 0.5~1 个百分点。

3.2 核心思路
这是我们这次参赛的一大亮点和创新点,就是成功地在深度学习上应用了一种类似于 AdaBoost 的做法,通过训练多层来不断修复前面层的偏差。我们在分析数据的时候发现,一个模型的输出是具有类别倾向性的,所以在某些类别上可能全对,而在某些类别上可能全错,所以我们针对这种偏差做了一些改进,通过人为地定义偏差的计算方式,指导下一层模型更多关注那些错的多的类,从而达到整体效果的提升。

通过用这种方法,单模型 Score 有了质的飞跃,平均提升都在 1.5 个百分点(FastText 因模型过于简单,提升空间有限),而 10 层的 RNN 则更是在用全部训练集 finetune 之后,分数直接从 0.413 飙升到 0.42978,可谓真是用单模型探索数据的极限了。

这种方法的优势在于,一般只要不断加深训练层数,效果就会提升,但缺点却在于它抹平了模型的差异性,对于模型融合效果不友好。
3.3 模型融合
模型融合依靠差异性,而我们模型的差异性在前面已经近乎被抹平,所以又另寻他路,用了另外两个方法:
最终模型主要是 5 个 10 层模型的概率加权融合,分数在 0.43506。
4. 结束语
这次比赛收获很大,总结起来就是:
最后,还是要感谢知乎等组织举办的这次比赛,也感谢北邮模式识别实验室的大力支持!
雷峰网版权文章,未经授权禁止转载。详情见转载须知。





