2
| 本文作者: 奕欣 | 2016-11-01 18:52 |
人无时不刻不在呼吸,而动辄爆表的 PM2.5,挣扎的雾霾让我们不禁忧虑起自身的健康来。
在一年以前,IBM 研究院推出了 Green Horizon项目,雷锋网此前也做过报道。Green Horizon 利用IBM的机器学习技术及物联网技术(IoT),从大数据中挖掘从天气到污染指数的一系列海量信息,以反复的迭代及自适应的调整系统,锻造出世界上最为精确的能源和环境预测系统。
IBM 首先把试点城市选在了南非的约翰内斯堡,与当地的研究机构进行协作。面对不断恶化的大气环境及气候变化,它们又会做出怎样的尝试呢?日前,驻该机构的 IBM 科学家 Tapiwa Chiwewe 与 IBM的 Chris Sciacca 进行了一次访谈,雷锋网摘编如下,未经许可不得转载。

Tapiwa Chiwewe
Chris Sciacca(下称 Sciacca):
目前这个环境预测系统进行到了怎样的阶段?
Tapiwa Chiwewe(下称 TC):
此前试点城市能够成功预测明天的环境状况,不过经过我们的努力,能够将这一时间延长到七天。
Sciacca:
那么,这个预测系统目前达到了怎样的精度?
TC:
现在能够达到 10 km*10 km 的空间分布率,而如果能增加更多的计算源,这一数字还能提升到 1 km*1 km 的高分辨率。
Sciacca:
如果要用预测结果做决策,精度要达到怎样的水平?
TC:
如果这些判断要用于决策的话,准确度能达到 70% 以上(包括一些明显的、肉眼可排除的错误)就可以称得上是很不错的结果了。而预测污染指数为环境提供公共预警信号肯定是大有裨益。
Sciacca:
我们都知道,在一天内或者一个地点中污染物的数量不可避免地会存在一定波动,那么这一数字与预测结果相比存在多少误差?
TC:
污染情况的波动取决于特定的天气状况。一些会造成强烈影响的天气状况(如强风、降雨、低气压等)能够在几个小时内迅速改变污染指数。而空气质量的预测主要借助的是天气模型来捕获上述容易影响污染状况的信息并做出调整,因此误差的规模就会减小很多。
Sciacca:
目前阶段及未来,我们是否能准确判断污染源?
TC:
污染源对于预测系统而言是另一个全新的命题,因为它需要对每个污染源进行判断,包括直接排放量、天气影响,伴随化学反应产生的二次污染等。
我们实际上可以追踪污染源来自什么样的地点。但它需要大量的数据源模型,且不能包含目前的试点。不过它可能是未来商业化的一个变现手段。另外,风是一个比较简单的判断因素,如果我们只考虑污染物的飘散状况,这个模型就会相对简单。
Sciacca:
要让这个系统顺利运转,我们需要什么样的支持?
TC:
实时传感器的数据当然必不可少。日常的天气预测可以以三天为界,并通过在线站点进行分析与整合。
Sciacca:
数据的来源是什么,又是如何进行收集的?
TC:
数据源于三个南非的空气监测网络,为约翰内斯堡、Thswane及瓦尔河监测中心。在三个网络点间,有 21 个监测站,按照南非空气质量数据中心的要求收集数据。我们准备将这一功能增加到 IBM 的 The Weather Company 商业计划中。
Sciacca:
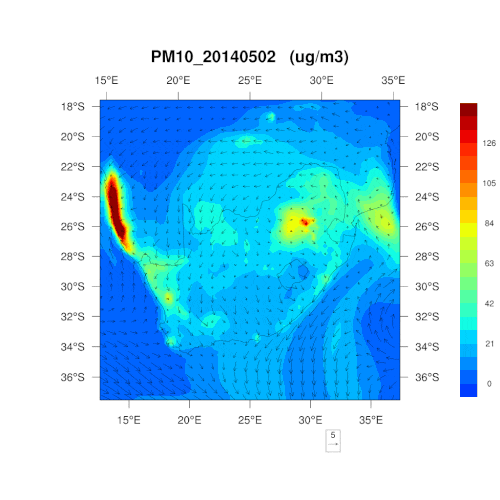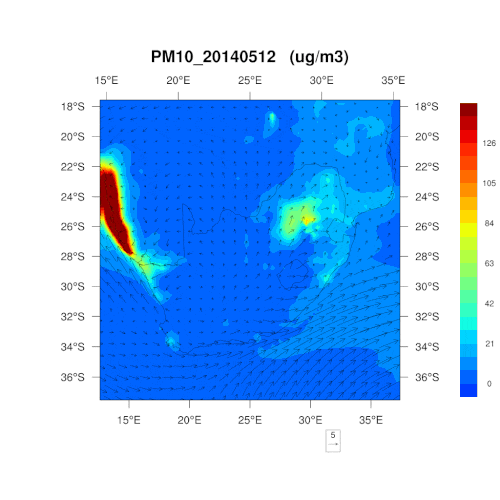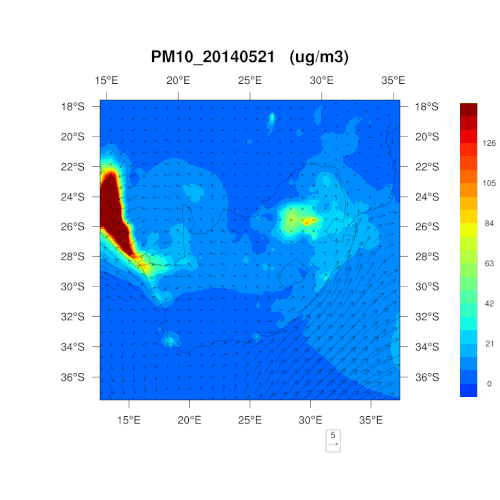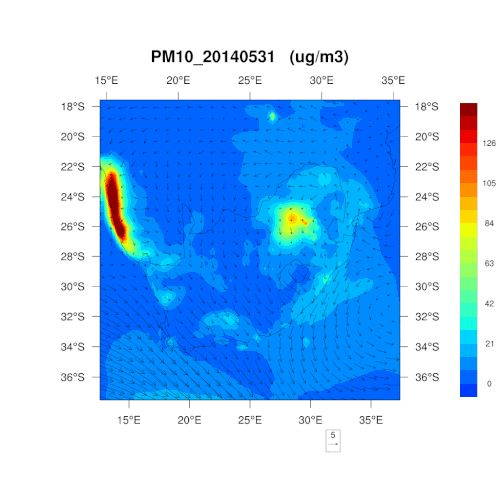
是否能为我们解释一下采用 PM10、PM2.5和二氧化氮这三个指标的原因?可否简单理解为,这三项为最“简单粗暴”的判断标准?
TC:
在监测之时,那些容易对人类、野生动植物及环境的健康造成影响的污染物自然首当其冲。南非通常每五年就会重新制定一次空气质量管理计划,明确首要关注的污染物,考虑所可能造成的危害,对干预策略的有效性进行判断,以控制空气污染。
Sciacca:
约翰内斯堡的哪些信息能够作为数据源?
TC:
数据的质量会以多种形式从不同站点收集,包括读数记录、采样间隔的时间、还有读数的准确性。这些都受监测站设备维护状况的影响。
Sciacca:
后续将有什么研究计划?
TC:
除了收集更多的数据,我们计划推出API,开发人员能够基于此创建为消费者和企业使用的应用程序。
如果你对他的研究感兴趣,欢迎阅读他的论文:Machine Learning Based Estimation of Ozone Using Spatio-Temporal Data from Air Quality Monitoring Stations
推荐阅读:
深度 | 从纽约到湾区,73岁的 IBM 凭借 Watson 一路向西
雷峰网原创文章,未经授权禁止转载。详情见转载须知。





