0
| 本文作者: AI研习社 | 2020-03-27 18:05 |

用机器学习方法对电网中的二氧化碳排放强度进行短期预测
基于图卷积神经网络的高保真3D人脸重建
BERTology入门:解读BERT的工作原理
DymSLAM:基于几何运动分割的动态场景重建
The Virtual Tailor: 基于人体姿态、形状和服装类型的3D服装预测
论文名称:Short-Term Forecasting of CO2 Emission Intensity in Power Grids by Machine Learning
作者:Kenneth Leerbeck /Peder Bacher /Rune Junker /Goran Goranović /Olivier Corradi /Razgar Ebrahimy /Anna Tveit /Henrik Madsen
发表时间:2020/3/10
论文链接:https://paper.yanxishe.com/review/14223?from=leiphonecolumn_paperreview0327
推荐原因
1 核心问题
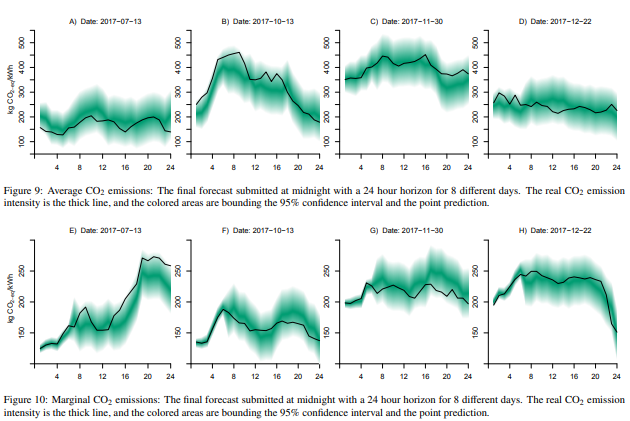
本文主要解决的是用机器学习方法来预测丹麦招标地区中电网二氧化碳的排放强度,区分平均排放量和边际排放量的问题
2 创新点
本文使用多变量线性回归模型建模,使用傅立叶序列来对季节波动进行衡量,使用Splines来捕获非线性特征。在面对大量属性时,本文结合了Lasso以及前向特征选择算法来进行特征选择。在最后的softmax层中根据不同验证集的平均RMSE使用权重平均模型进行了处理。
3 研究意义
本文发现边际排放量和DK2区域的状况完全不同,说明了边际发电机位于相邻区域中,并且提出的方法可以在不需要提前详细了解的情况下,用于欧洲电网中的任意投标区域。
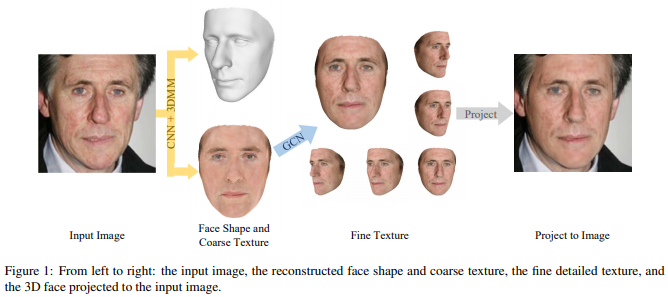
论文名称:Towards High-Fidelity 3D Face Reconstruction from In-the-Wild Images Using Graph Convolutional Networks
作者:Jiangke Lin /Yi Yuan /Tianjia Shao /Kun Zhou
发表时间:2020/3/12
论文链接:https://paper.yanxishe.com/review/14158?from=leiphonecolumn_paperreview0327
推荐原因
该文章是CVPR2020的人脸重建文章。
在过去几年中,基于3DMM的方法在从单视图图像恢复3D面部形状方面取得了巨大的成功。然而通过这种方法恢复的面部纹理缺乏输入图像中所表现的保真度。最近也有一些工作使用在高质量面部纹理UV贴图的大规模数据集中训练的生成网络,能够生成高质量的面部纹理,但数据集很难准备且没有公开。
本文介绍了一种从单视角自然图像重建具有高保真纹理的3D面部形状的方法,无需大规模的面部纹理数据库。其主要思想是使用来自输入图像的面部细节来优化基于3DMM方法生成的初始纹理,使用图卷积网络来重建网格顶点的详细颜色而不是重建纹理贴图。实验表明文章方法可以产生高质量的重建结果,优于最新的方法。
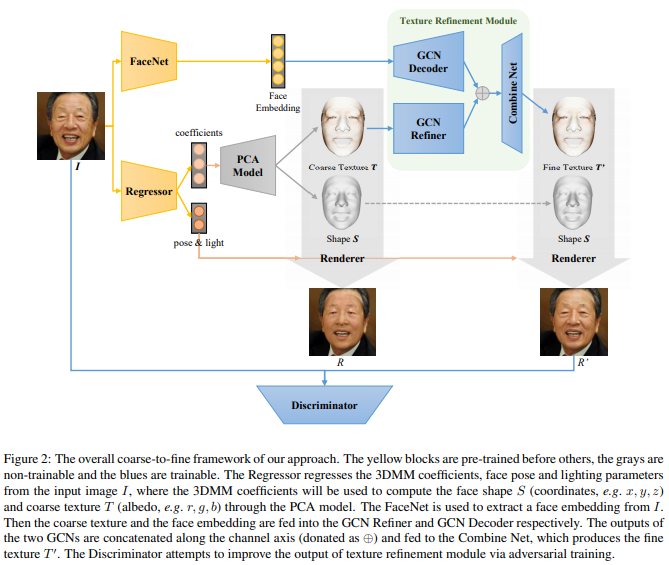
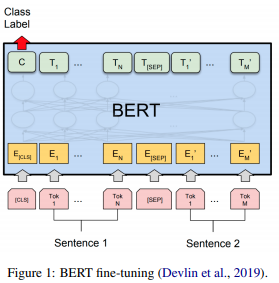
论文名称:A Primer in BERTology: What we know about how BERT works
作者:Anna Rogers
发表时间:2020/2/7
论文链接:https://paper.yanxishe.com/review/13947?from=leiphonecolumn_paperreview0327
推荐原因
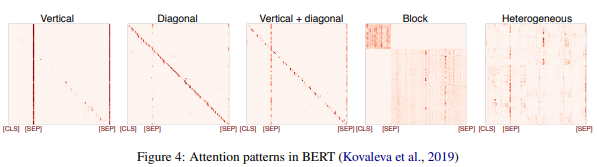
本文是一篇综述性文章,概述了目前学术界对Bert已取得的研究成果,并且对后续的研究也进行了展望,适合于初入BERT模型的人员学习。本文的框架作者主要从BERT网络结构、BERT embeddings、BERT中的句法知识(Syntactic knowledge)、语义知识(Semantic knowledge)和知识库(World knowledge)以及Self-attention机制等角度对当下学术界对BERT的研究进行了说明,基于前面的介绍,作者对BERT是如何训练、当模型过于复杂时应给如何解决等问题给出了相应的解决方案。最后作者对BERT未来的研究方向以及需要解决的问题提出了展望。
论文名称:DymSLAM:4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation
作者:Chenjie Wang /Bin Luo /Yun Zhang /Qing Zhao /Lu Yin /Wei Wang /Xin Su /Yajun Wang /Chengyuan Li
发表时间:2020/3/10
论文链接:https://paper.yanxishe.com/review/13904?from=leiphonecolumn_paperreview0327
推荐原因
大多数SLAM算法都是基于静态场景假设,但实际情况下大多数场景都是动态的,包含动态对象,因此此类方法都不适用。
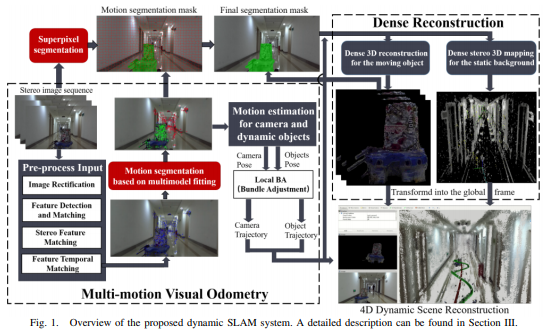
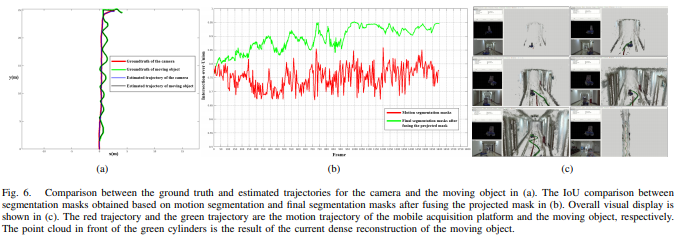
本文提出了DymSLAM,一种基于动态立体实际SLAM系统,能够重建包含刚性运动对象的4D(3D+时间)动态场景。DymSLAM的唯一输入是立体视频,输出静态环境的密集图,运动对象的3D模型以及相机和运动对象的轨迹。系统首先使用传统SLAM方法检测并匹配连续帧直接的兴趣点,然后通过多模型拟合算法将属于不同运动模型(包括自我运动和刚性对象运动)的兴趣点进行分割。基于自我运动的兴趣点预测相机轨迹和静态背景,基于刚性对象运动的兴趣点用于估计对象相对于相机的相对运动并重建对象的3D模型。最后再3D对象的运动融合到环境的3D地图中,以获得4D序列。
问题提出了包含刚性运动物体的SLAM系统,能够重建场景中刚性运动对象的模型及其运动轨迹,可以用于机器人的动态物体避障等众多应用。
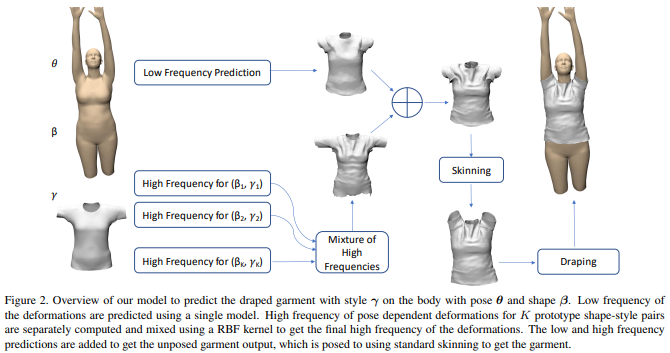
论文名称:The Virtual Tailor: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style
作者:Patel Chaitanya /Liao Zhouyingcheng /Pons-Moll Gerard
发表时间:2020/3/10
论文链接:https://paper.yanxishe.com/review/13854?from=leiphonecolumn_paperreview0327
推荐原因
如何快速准确逼真地模拟、预测人体衣服的形变是计算机图形学中的一个重要问题,在诸如AR/VR、虚拟试衣等众多领域都有着应用。
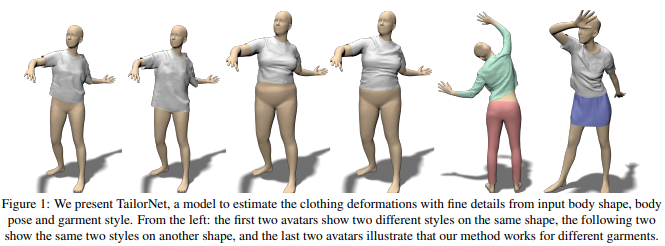
本文提出了TailorNet神经网络模型,其可以根据人体形状、姿态和服装类型来预测衣服的形变,并同时保留衣服的褶皱等局部细节。文章技术的核心是将衣服的形状分解为高频部分和低频部分,其中低频部分的信息从人体形状、姿态和衣服类别预测,高频部分的细节从形状风格相关的姿态模型来预测并混合得到。作者将其构造的包含55800帧的数据集开源,项目主页https://virtualhumans.mpi-inf.mpg.de/vtailor。
雷锋网雷锋网雷锋网
相关文章:
今日 Paper | 深度循环神经网络;PoseNet3D;AET vs. AED;光场视差估计等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。





