0

CVPR 2020 | 检测视频中关注的视觉目标
CVPR 2020 | D3Feat:密集检测和3D局部特征描述的联合学习
CVPR 2020 | 搜索中央差分卷积网络以进行面部反欺
模型的密度估计能力、序列生成能力、BLEU分数之间到底是什么关系
在元学习和具体任务的学习之间寻找平衡
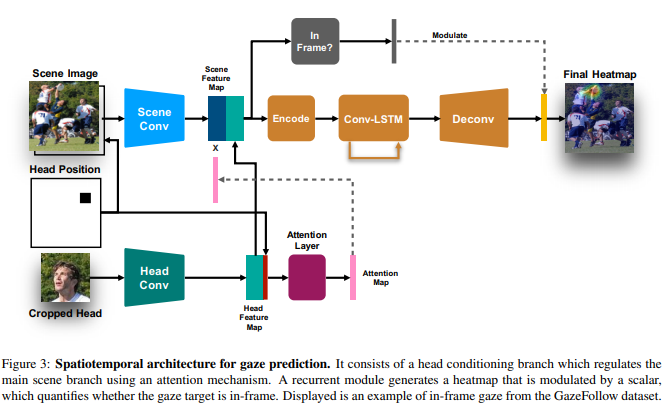
论文名称:Detecting Attended Visual Targets in Video
作者:Chong Eunji /Wang Yongxin /Ruiz Nataniel /Rehg James M.
发表时间:2020/3/5
论文链接:https://paper.yanxishe.com/review/13533?from=leiphonecolumn_paperreview0320
推荐原因
这篇论文被CVPR 2020接收,要解决的是检测视频中关注目标的问题。具体来说,目标是确定每个视频帧中每个人的视线,并正确处理帧外的情况。所提的新架构有效模拟了场景与头部特征之间的动态交互,以推断随时间变化的关注目标。同时这篇论文引入了一个新数据集VideoAttentionTarget,包含现实世界中复杂和动态的注视行为模式。在该数据集上进行的实验表明,所提模型可以有效推断视频中的注意力。为进一步证明该方法的实用性,这篇论文将预测的注意力图应用于两个社交注视行为识别任务,并表明所得分类器明显优于现有方法。

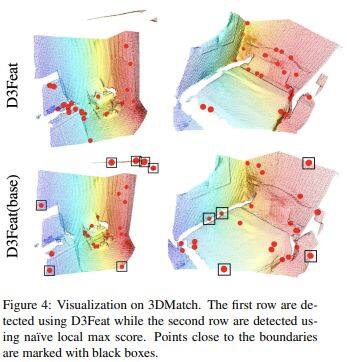
论文名称:D3Feat: Joint Learning of Dense Detection and Description of 3D Local Features
作者:Bai Xuyang /Luo Zixin /Zhou Lei /Fu Hongbo /Quan Long /Tai Chiew-Lan
发表时间:2020/3/6
论文链接:https://paper.yanxishe.com/review/13946?from=leiphonecolumn_paperreview0320
推荐原因
这篇论文被CVPR 2020接收,关注的是对3D特征检测器的研究。
这篇论文将3D全卷积网络用于3D点云,并提出一种克服3D点云固有密度变化的关键点选择策略,并进一步提出一种在训练过程中由实时特征匹配结果指导的自监督探测器损失。新方法可以密集预测每个3D点的检测得分和描述特征。新方法在3DMatch和KITTI数据集上评估了室内和室外场景的最新结果,并在ETH数据集上显示出强大的泛化能力。在实际应用中通过采用可靠的特征检测器,对少量特征进行采样就足以实现准确、快速的点云对准。

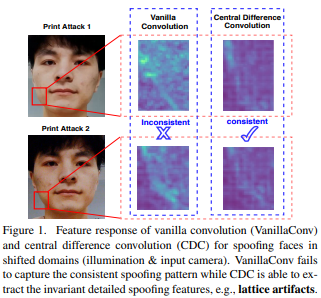
论文名称:Searching Central Difference Convolutional Networks for Face Anti-Spoofing
作者:Yu Zitong /Zhao Chenxu /Wang Zezheng /Qin Yunxiao /Su Zhuo /Li Xiaobai /Zhou Feng /Zhao Guoying
发表时间:2020/3/9
论文链接:https://paper.yanxishe.com/review/13945?from=leiphonecolumn_paperreview0320
推荐原因
这篇论文被CVPR 2020接收,考虑的是面部反欺诈的问题。
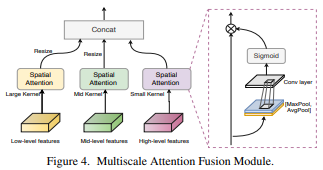
这篇论文提出一种基于中央差分卷积的帧级面部反欺诈方法,能够通过汇总强度和梯度信息来捕获固有的详细模式。用中央差分卷积构建的网络称为中央差分卷积网络(Central Difference Convolutional Network,CDCN)。与使用原始卷积构建的网络相比,CDCN能提供更强大的建模能力。此外,在经过专门设计的中央差分卷积搜索空间上,神经架构搜索可以用于发现更强大的网络结构,将其与多尺度注意力融合模块组装在一起可以进一步提高性能。
论文名称:On the Discrepancy between Density Estimation and Sequence Generation
作者:Lee Jason /Tran Dustin /Firat Orhan /Cho Kyunghyun
发表时间:2020/2/17
论文链接:https://paper.yanxishe.com/review/13949?from=leiphonecolumn_paperreview0320
推荐原因
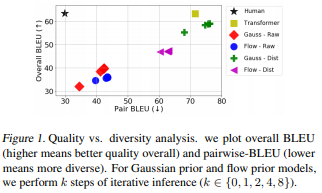
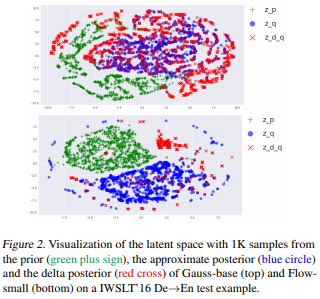
密度估计、序列生成这两件任务,一般看来似乎是没有什么关系的。但这篇论文研究后发现,一个模型的密度估计能力、序列生成能力、BLEU分数三者之间其实有紧密的联系。
如果把基于给定的输入 x 预测 y 的分布看作是一个密度估计任务,那么机器翻译、文本到语音转换之类的序列生成任务就都可以看作是密度估计,然后就可以进一步用密度估计中使用的条件对数似然测试来评价模型。
不过,我们都这个测试和序列生成模型本身的设计目标还是有所不同的,但似乎没人研究过其中的区别有多大。在这篇论文中,作者们在多项测试中对比了不同的密度估计结果和BLEU分数之间的关系,发现两者间的关系受几条微妙的因素影响,比如对数似然和BLEU高度相关,尤其是对于同一个家族的模型(各种自回归模型,有同样的参数先验的隐含变量模型)。
在做了许多对比总结后,作者们最后建议,如果想要获得很快的序列生成速度,可以在设计模型时选用带有隐含变量的非自回归模型,并且配合使用简单的先验。
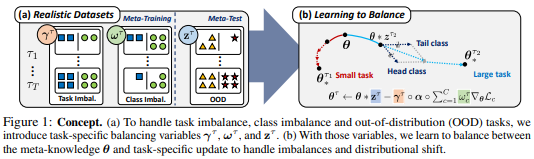
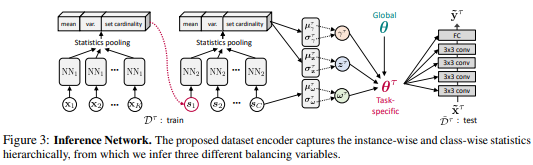
论文名称:Learning to Balance: Bayesian Meta-Learning for Imbalanced and Out-of-distribution Tasks
作者:Hae Beom Lee /Hayeon Lee /Donghyun Na /Saehoon Kim /Minseop Park /Eunho Yang /Sung Ju Hwang
发表时间:2019/9/26
论文链接:https://paper.yanxishe.com/review/13948?from=leiphonecolumn_paperreview0320
推荐原因
机器学习领域的研究员们希望模型能有更好的泛化能力,不要太过拟合到具体任务的设置里,所以近几年元学习(meta-learning)的研究非常火热。
但元学习的研究有时候也掉进了固定的套路里,比如假定要学的多个任务里,每个任务中出现的样本数量、类别数量都是一致的,所以他们也就会让模型从每个任务中获得同样多的元知识 —— 但实际中,不同任务中的样本数量、类别数量完全可以是不同的,不同任务的元知识含量也是不同的。所以这种做法并不好。
除此之外,当前的许多元学习研究中并不考虑见到的全新数据的分布如何,有可能这些数据的分布和学过的数据的分布完全不同,就没办法用来提高模型的表现。
为了解决这些实际问题,这篇论文提出了一种新的元学习模型,它会在“元学习”和“针对具体任务的学习”两件事之间寻找平衡,不再是像以往的模型一样对所有状况统一处理。实验表明这种方法的表现大大优于此前所有的元学习方法。
这篇论文被 ICLR2020 接收为口头报告论文。

雷锋网雷锋网雷锋网
相关文章:
今日 Paper | 物体渲染;图像和谐化;无偏数据处理方法;面部伪造检测等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。





