0
| 本文作者: AI研习社 | 2020-03-03 11:49 |

Sketch Less for More:基于细粒度草图的动态图像检索
ABCNet:基于自适应Bezier-Curve网络的实时场景文本定位
通过逐步增加蒙版区域来修复图像
BlockGAN:从未标记的图像中学习3D对象感知场景表示
用于行人重识别的交叉分辨对抗性双重网络
论文名称:Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
作者:Bhunia Ayan Kumar /Yang Yongxin /Hospedales Timothy M. /Xiang Tao /Song Yi-Zhe
发表时间:2020/2/24
论文链接:https://paper.yanxishe.com/review/12442?from=leiphonecolumn_paperreview0303
推荐原因
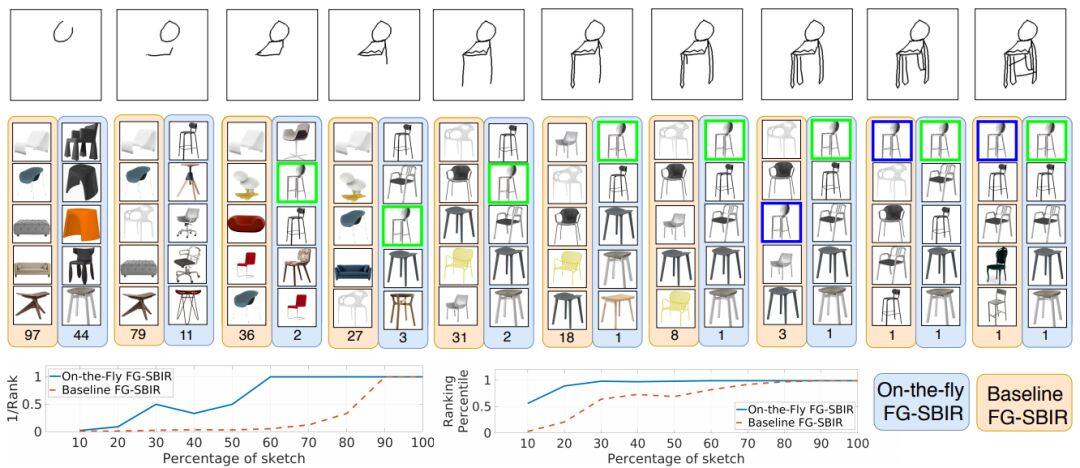
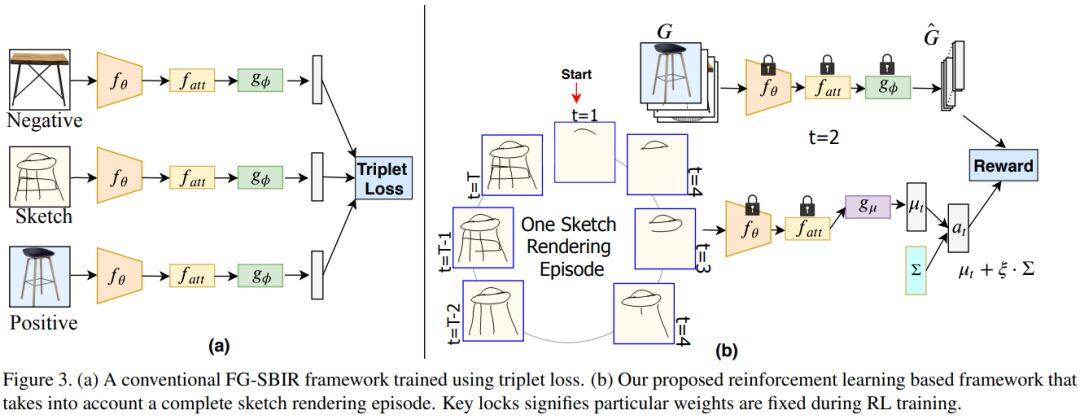
这篇论文被CVPR 2020接收,考虑的是基于草图的细粒度图像检索,即在给定用户查询草图的情况下检索特定照片样本的问题。
绘制草图花费时间,且大多数人都难以绘制完整而忠实的草图。为此这篇论文重新设计了检索框架以应对这个挑战,目标是以最少笔触数检索到目标照片。这篇论文还提出一种基于强化学习的跨模态检索框架,一旦用户开始绘制,便会立即开始检索。此外,这篇论文还提出一种新的奖励方案,该方案规避了与无关的笔画笔触相关的问题,从而在检索过程中为模型提供更一致的等级列表。在两个公开可用的细粒度草图检索数据集上的实验表明,这篇论文所提方法比当前最佳方法具有更高的早期检索效率。
论文名称:ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network
作者:Liu Yuliang /Chen Hao /Shen Chunhua /He Tong /Jin Lianwen /Wang Liangwei
发表时间:2020/2/24
论文链接:https://paper.yanxishe.com/review/12441?from=leiphonecolumn_paperreview0303
推荐原因
这篇论文被CVPR 2020接收,考虑的是场景文本检测和识别的问题。
现有方法基于字符或基于分段,要么在字符标注上成本很高,要么需要维护复杂的工作流,都不适用于实时应用程序。这篇论文提出了自适应贝塞尔曲线网络(Adaptive Bezier-Curve Network ,ABCNet),包括三个方面的创新:1)首次通过参数化的贝塞尔曲线自适应拟合任意形状文本;2)设计新的BezierAlign层,用于提取具有任意形状的文本样本的准确卷积特征,与以前方法相比显著提高精度;3)与标准图形框检测相比,所提贝塞尔曲线检测引入的计算开销可忽略不计,从而使该方法在效率和准确性上均具优势。对任意形状的基准数据集Total-Text和CTW1500进行的实验表明,ABCNet达到当前最佳的准确性,同时显著提高了速度,特别是在Total-Text上,ABCNet的实时版本比当前最佳方法快10倍以上,且在识别精度上极具竞争力。


论文名称:Learning to Inpaint by Progressively Growing the Mask Regions
作者:Hedjazi Mohamed Abbas /Genc Yakup
发表时间:2020/2/21
论文链接:https://paper.yanxishe.com/review/12259?from=leiphonecolumn_paperreview0303
推荐原因
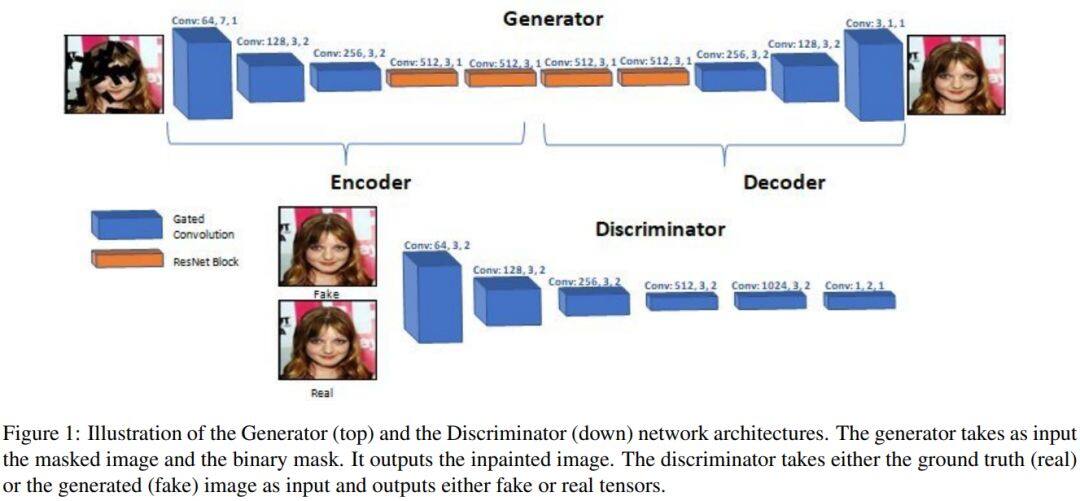
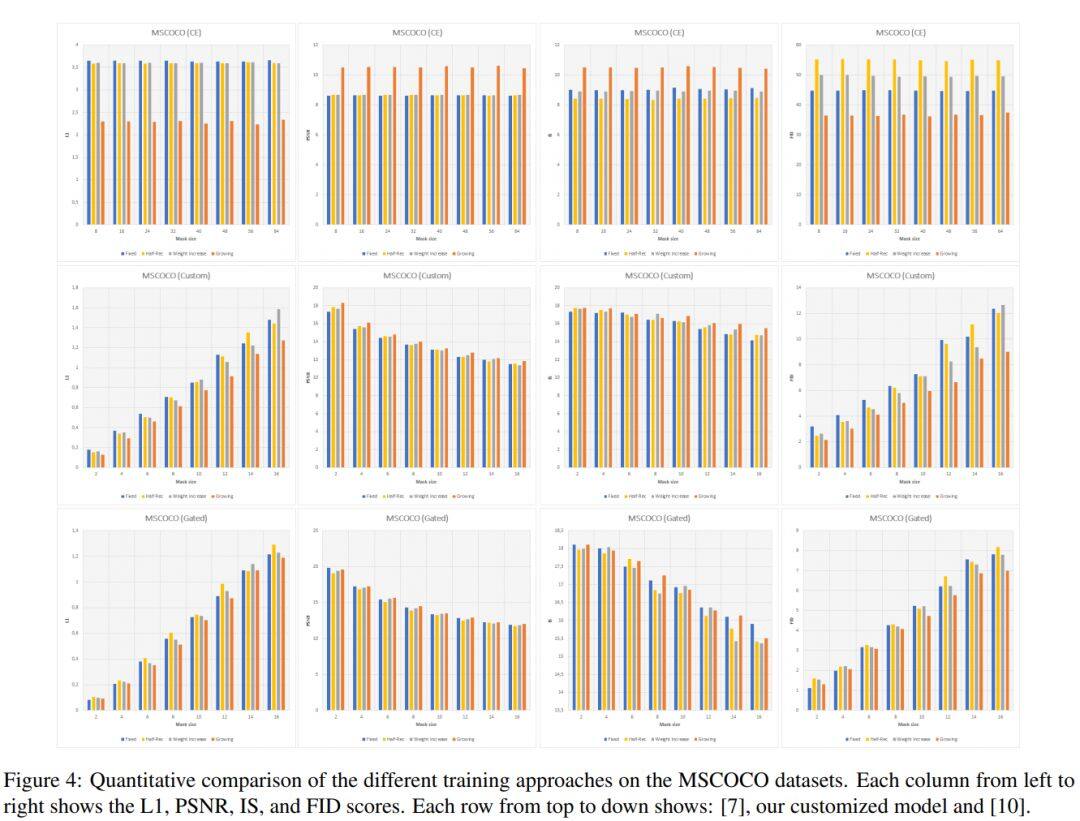
这篇论文考虑的是图像修复问题。
生成模型可以产生视觉上合理的图像,但是随着被遮挡区域的增大,以往的方法难以生成正确的结构和颜色。这篇论文对这个问题引入了一种新的课程样式训练方法,在训练时间内逐渐增加遮罩区域的大小,而在测试时,用户可以在任意位置给出随机尺寸的遮罩。这种训练方法可以使得生成对抗模型的训练更加平稳,提供更好的颜色一致性并且捕捉对象的连续性。
论文名称:BlockGAN: Learning 3D Object-aware Scene Representations from Unlabelled Images
作者:Nguyen-Phuoc Thu /Richardt Christian /Mai Long /Yang Yong-Liang /Mitra Niloy
发表时间:2020/2/20
论文链接:https://paper.yanxishe.com/review/12258?from=leiphonecolumn_paperreview0303
推荐原因
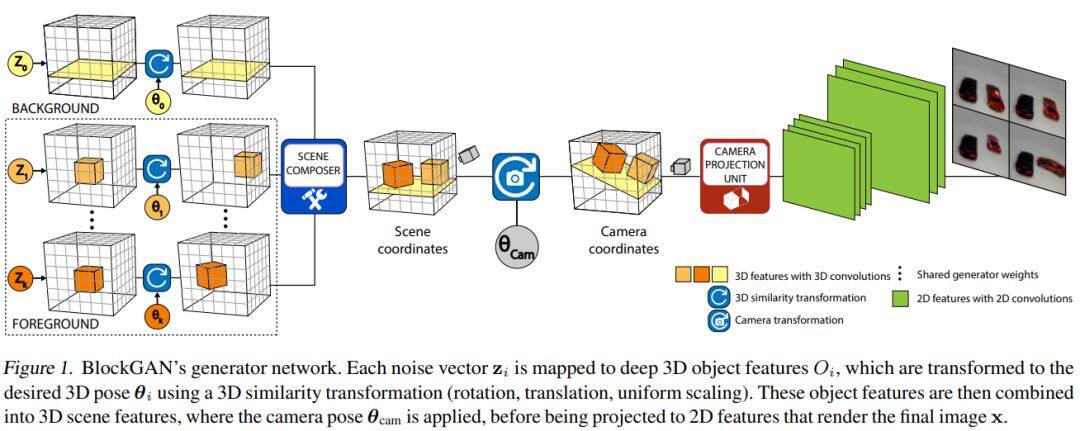
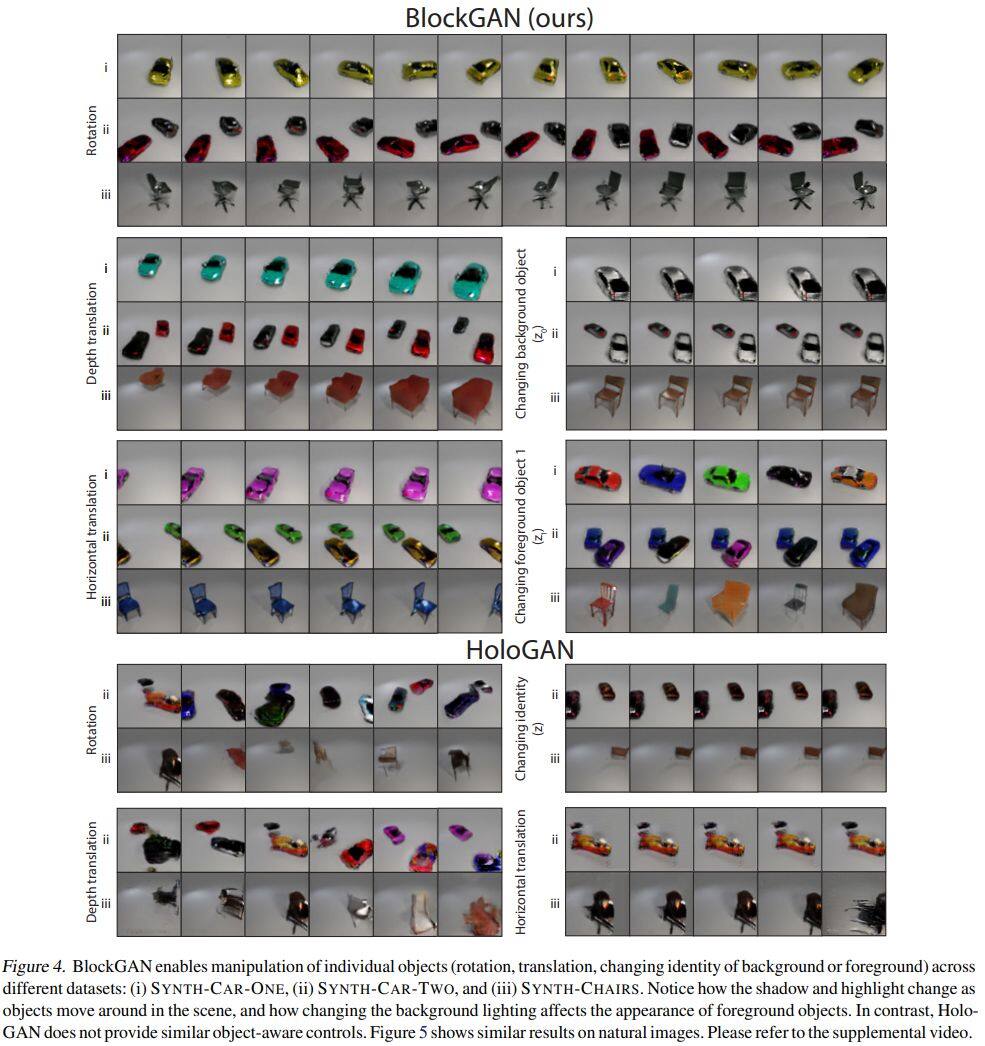
这篇论文提出了一个名为BlockGAN的图像生成模型,可以直接从未标注的2D图像中学习对象感知的3D场景表示。BlockGAN首先生成背景和前景对象的3D特征,然后将它们组合为整个场景的3D特征,最后将它们渲染为逼真的图像。BlockGAN可以推理出对象的外观(例如阴影和照明)之间的遮挡和交互作用,并提供对每个对象的3D姿势和身份的控制,同时保持图像的逼真度。BlockGAN的效果可以在项目主页中查看。
论文名称:Cross-Resolution Adversarial Dual Network for Person Re-Identification and Beyond
作者:Li Yu-Jhe /Chen Yun-Chun /Lin Yen-Yu /Wang Yu-Chiang Frank
发表时间:2020/2/19
论文链接:https://paper.yanxishe.com/review/12257?from=leiphonecolumn_paperreview0303
推荐原因
这篇论文要解决的是行人重识别问题。
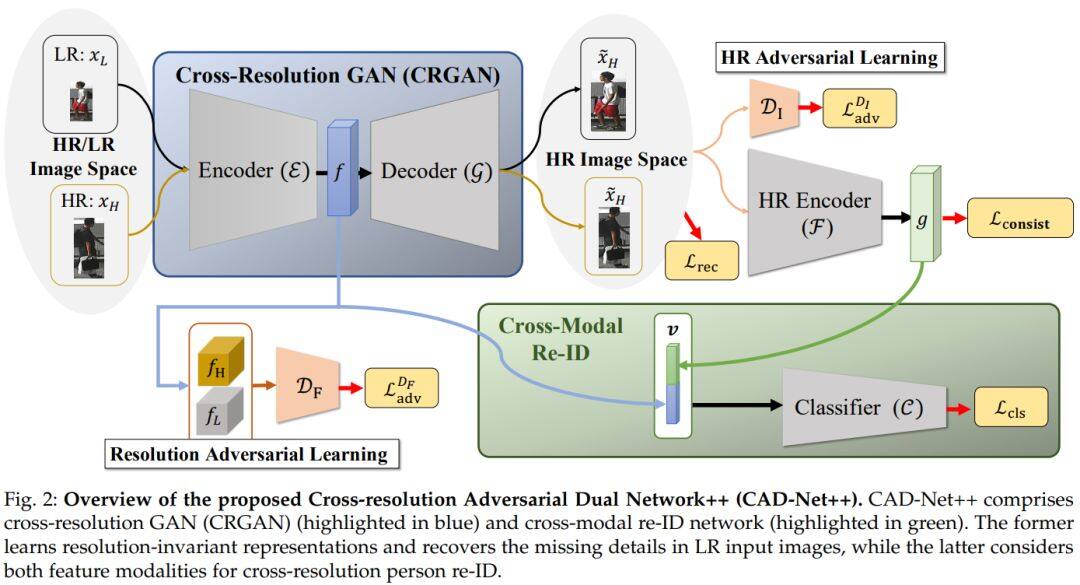
考虑到真实场景中摄像机和目标人之间距离不同可能会带来分辨率不匹配的情况,会降低行人重识别算法的表现。这篇论文提出了一种的新的生成对抗网络来解决跨分辨率的行人重识别,可以学习分辨率不变的图像表示,同时能恢复低分辨率输入图像丢失的细节,共同用于改善重识别的性能。在五个标准行人重识别基准上的实验结果证实了该方法的有效性,尤其是在训练过程中不知道输入分辨率的情况下。此外,两个车辆重识别基准测试的实验结果也证实了该模型在交叉分辨率视觉任务上的通用性。

为了更好地服务广大 AI 青年,AI 研习社正式推出全新「论文」版块,希望以论文作为聚合 AI 学生青年的「兴趣点」,通过论文整理推荐、点评解读、代码复现。致力成为国内外前沿研究成果学习讨论和发表的聚集地,也让优秀科研得到更为广泛的传播和认可。
我们希望热爱学术的你,可以加入我们的论文作者团队。
加入论文作者团队你可以获得
1.署着你名字的文章,将你打造成最耀眼的学术明星
2.丰厚的稿酬
3.AI 名企内推、大会门票福利、独家周边纪念品等等等。
加入论文作者团队你需要:
1.将你喜欢的论文推荐给广大的研习社社友
2.撰写论文解读
如果你已经准备好加入 AI 研习社的论文兼职作者团队,可以添加运营小姐姐的微信(ID:julylihuaijiang),备注“论文兼职作者”

雷锋网雷锋网雷锋网
相关文章:
今日 Paper | 自适应次梯度法;多域联合语义框架;无问答对分析;口语系统评价等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

