0
| 本文作者: AI研习社 | 2020-03-19 14:50 |

IGNOR: 基于深度学习的图像引导的物体渲染
基于域验证的图像和谐化
人体姿态估计中的无偏数据处理方法的研究
面部X射线,可进行更一般的面部伪造检测
即插即用(Plug and Play)的受限文本生成方法
论文名称:IGNOR: Image-guided Neural Object Rendering
作者:Thies Justus /Zollhöfer Michael /Theobalt Christian /Stamminger Marc /Nießner Matthias
发表时间:2018/11/26
论文链接:https://paper.yanxishe.com/review/13549?from=leiphonecolumn_paperreview0319
推荐原因
本文被ICLR 2020接收!文章提出了一种基于学习的图像引导的渲染技术,该技术将基于图像的渲染和基于GAN的图像合成相结合,可以生成重建对象的高真实感渲染结果。
文章技术的核心是如何处理视角相关的视觉效果,为了解决这个问题作者首先训练了一个基于特定对象的深度神经网络来合成目标对象与视角无关的外观。为了处理视角相关的效果,如物体表面的高光等,作者剔除了EffectsNet来进一步预测与视角相关的效果。作者在合成和真实数据上定性和定量的证明了文章方法的有效性。
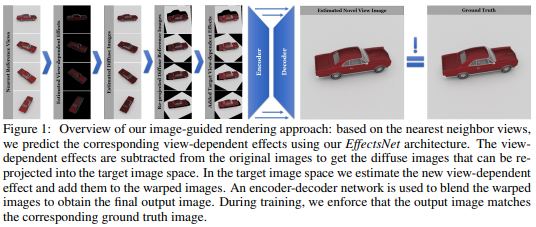
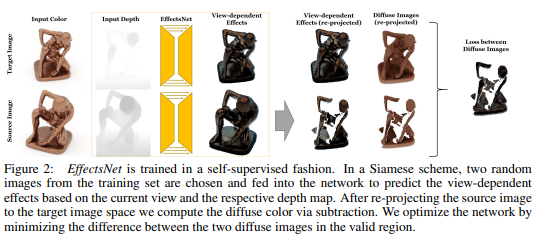
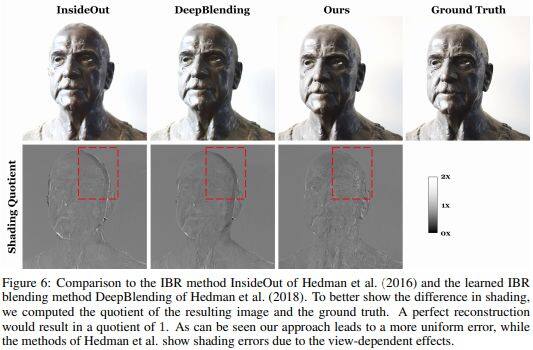
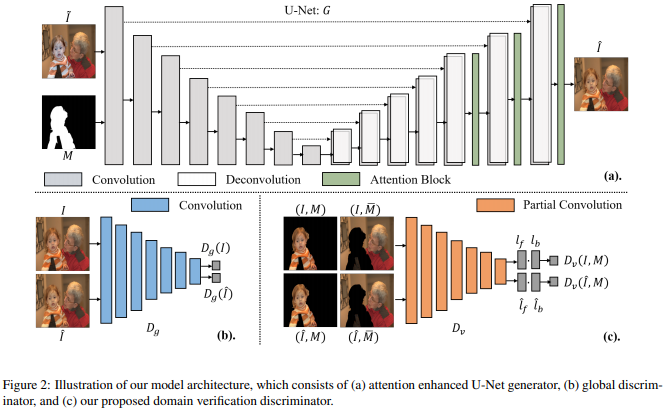
论文名称:Deep Image Harmonization via Domain Verification
作者:Wenyan Cong
发表时间:2020/1/1
论文链接:https://paper.yanxishe.com/review/13544?from=leiphonecolumn_paperreview0319
推荐原因
研究意义:
图像合成是图像处理中的重要操作,但是从背景或者其他图片转移颜色信息到前景上会严重降低合成图像的质量。目前没有用于图像协调的高质量公共可用数据集极大地阻碍了图像协调的发展技术。近年来,已经有少量的工作尝试用深度学习做图像和谐化,但成对的合成图和真实图极难获得。我们通过基于COCO合成的图像(分别是Adobe5k,Flickr,day2night)来贡献图像协调数据集,通过深度学习的训练生成监督信息,从而解决目前遇到的弊端。
创新点:
1、构建并公布了由四个子数据库组成的图像和谐化数据库。
2、提出了域验证 (domain verification) 的概念,尝试了基于域验证的图像和谐化算法。
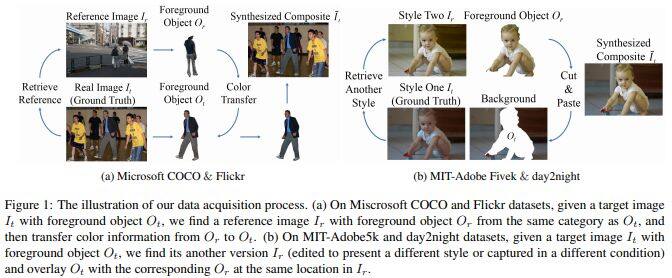
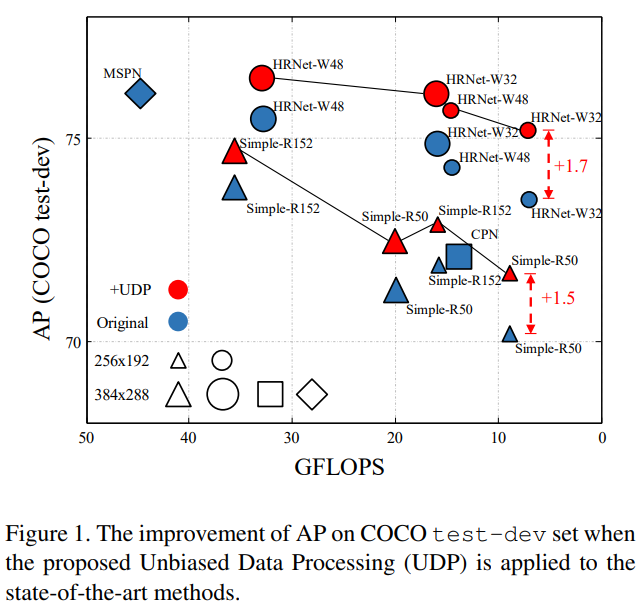
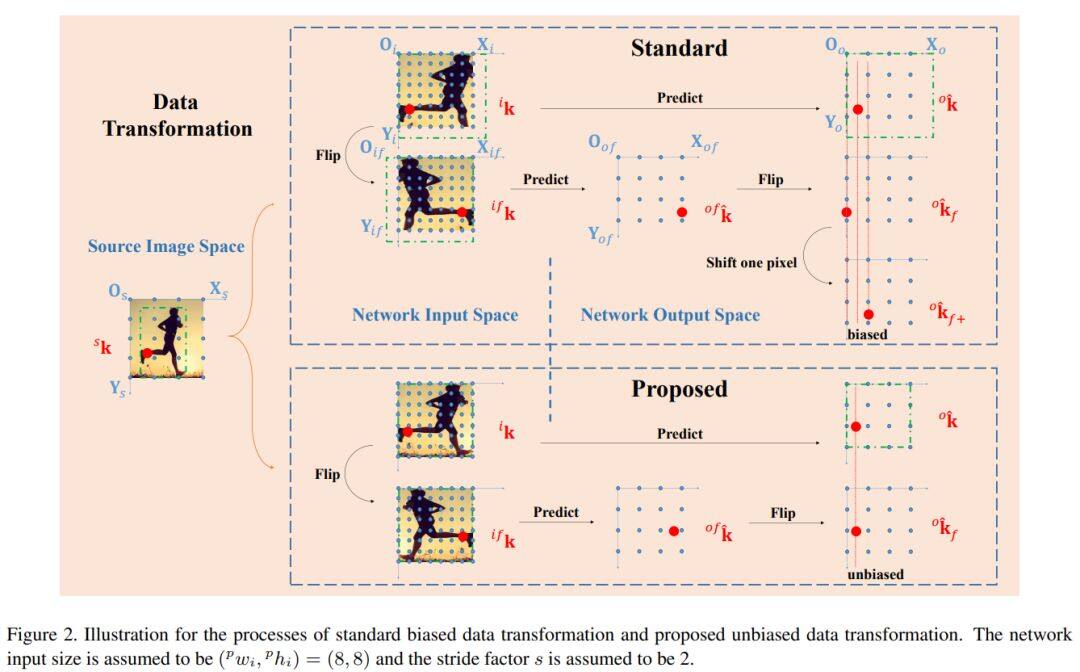
论文名称:The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
作者:Junjie Huang
发表时间:2019/12/1
论文链接:https://paper.yanxishe.com/review/13543?from=leiphonecolumn_paperreview0319
推荐原因
本文研究意义:
目前,对于人体姿势预测的研究主要局限于自上而下的方法。然而,对于训练和预测的基本组成部分,尚未在姿势预测中考虑数据的处理。基于此,本文以此为出发点,提出了有偏数据的处理在研究自上而下的姿态估计器中的作用。
本文的创新点:
1、UDP,解决了现有的SOTA人体姿态估计算法中标准编解码方法存在较大统计误差的问题。
2、该算法解决了由于翻转测试而导致的结果不对齐问题。
3、该算法即用即插,在基本不增加模型复杂度的情况下,有效提升了算法性能。
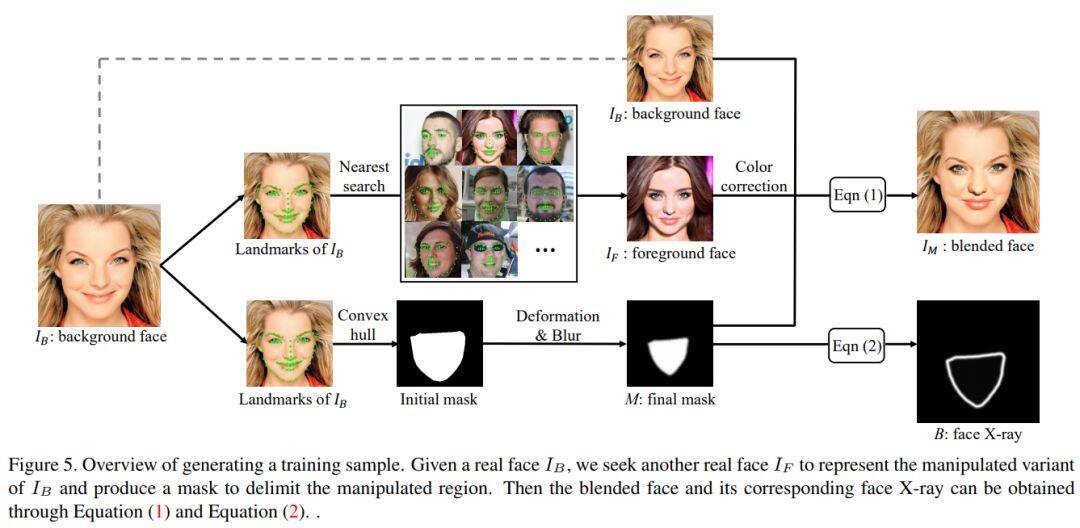
论文名称:Face X-ray for More General Face Forgery Detection
作者:Lingzhi Li1
发表时间:2019/12/1
论文链接:https://paper.yanxishe.com/review/13542?from=leiphonecolumn_paperreview0319
推荐原因
本文研究意义:
这篇文章是微软亚洲研究院的研究paper。在本文中,作者提出了一个方法---面部X射线,它既不需要了解换脸后的图像数据,也不需要知道换脸算法,就能对图像做『X-Ray』,鉴别出是否换脸,以及指出换脸的边界。
本文的创新点:
作者提出的新模型 Face X-Ray 具有两大属性:能泛化到未知换脸算法、能提供可解释的换脸边界。要获得这样的优良属性,诀窍就藏在换脸算法的一般过程中。在当下工业界中,盛行的大多数换脸算法一般可以分为检测、修改以及融合三部分。而本文标新立异之处在于,该新模型Face X-Ray是通过检测第三阶段产生的误差来进行实验的。

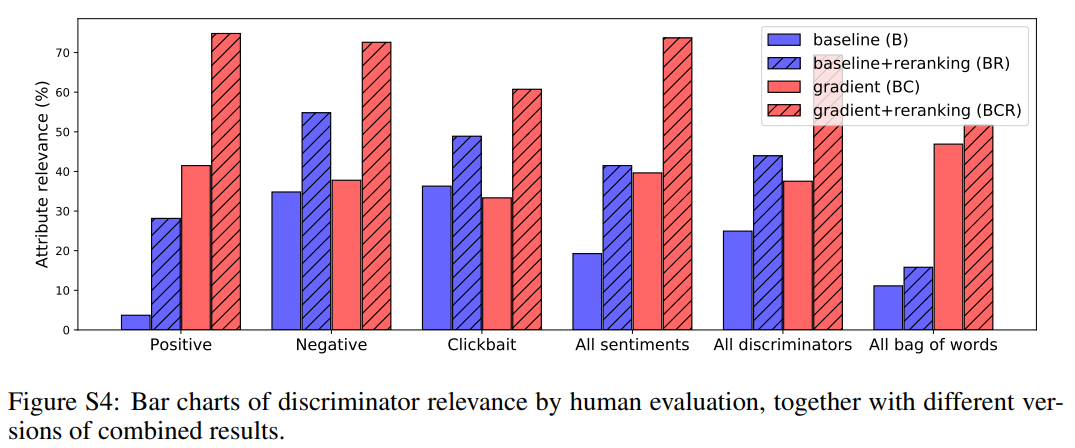
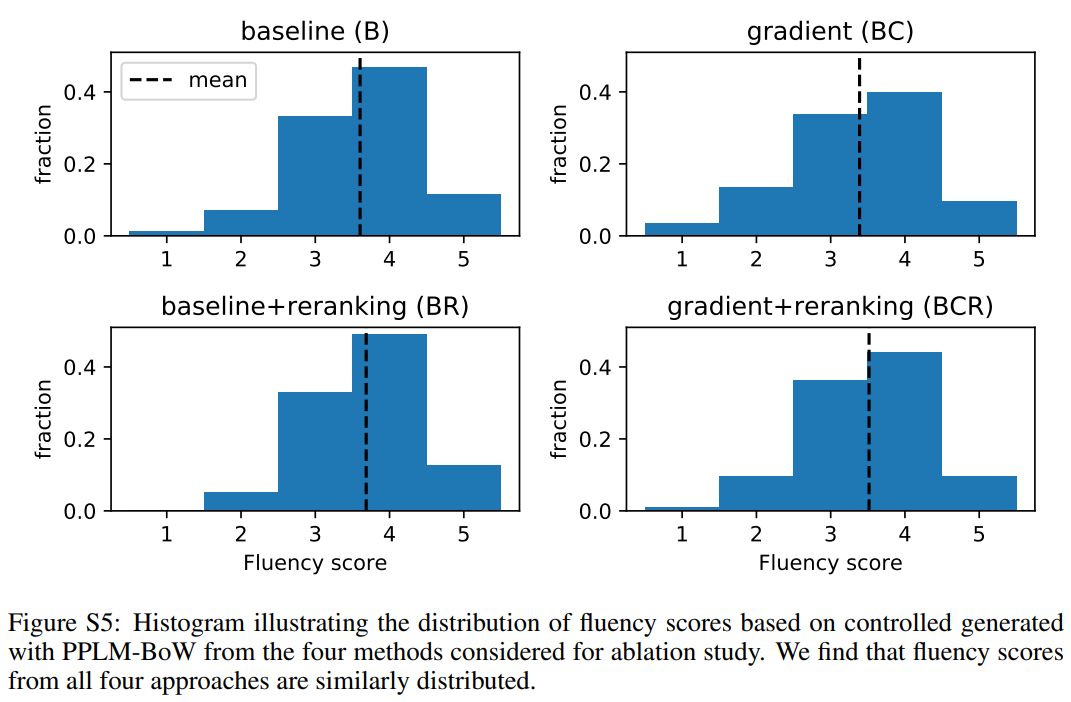
论文名称:PLUG AND PLAY LANGUAGE MODELS: A SIMPLE APPROACH TO CONTROLLED TEXT GENERATION
作者:Sumanth Dathathri
发表时间:2019/12/1
论文链接:https://paper.yanxishe.com/review/13541?from=leiphonecolumn_paperreview0319
推荐原因
本文研究意义:
作者在普通语言模型的基础上提出了一个用于建模生成句子中的不同属性的属性模型,该模型可以实现多种属性上的受限文本生成。此外,作者提出的新方法PPLM,是不需要改变原有语言模型的结构,只需要让两个模型同时训练,就可以实现属性控制效果的显著提升。
创新点:
1、提出了一种即插即用的受限文本生成方法--PPLM。
2、PPLM不需要改变语言模型的结构,只需要让这两个模型同时训练即可。

雷锋网雷锋网雷锋网
相关文章:
今日 Paper | CausalML;隐式函数;慢动作视频重建;交叉图卷积网络等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。





