0
| 本文作者: AI研习社 | 2020-03-05 16:01 |

Social-STGCNN:一种用于行人轨迹预测的社会时空图卷积神经网络
音频驱动的带自然头部姿态的说话人脸视频生成
用自适应实例归一化将学习从合成噪声转移到真实噪声去噪
CookGAN:食材图像合成
通过几何感知网络学习光场角度超分辨率
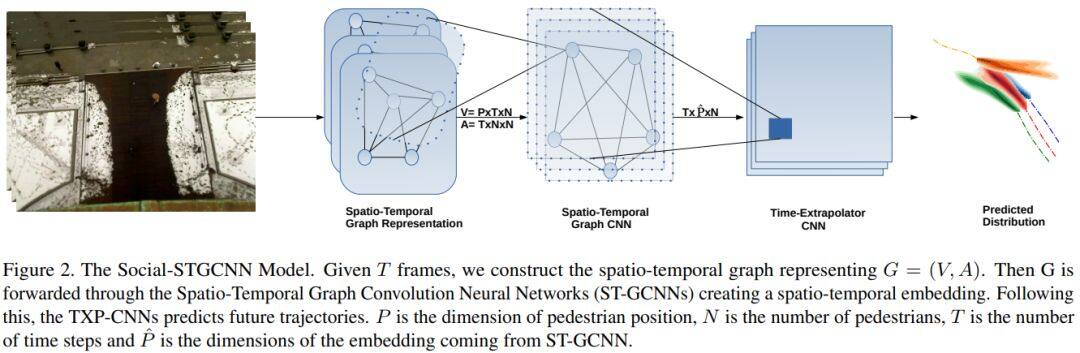
论文名称:Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction
作者:Mohamed Abduallah /Qian Kun /Elhoseiny Mohamed /Claudel Christian
发表时间:2020/2/27
论文链接:https://paper.yanxishe.com/review/12827?from=leiphonecolumn_paperreview0305
推荐原因
这篇论文被CVPR 2020接收,考虑的是行人轨迹预测的问题。
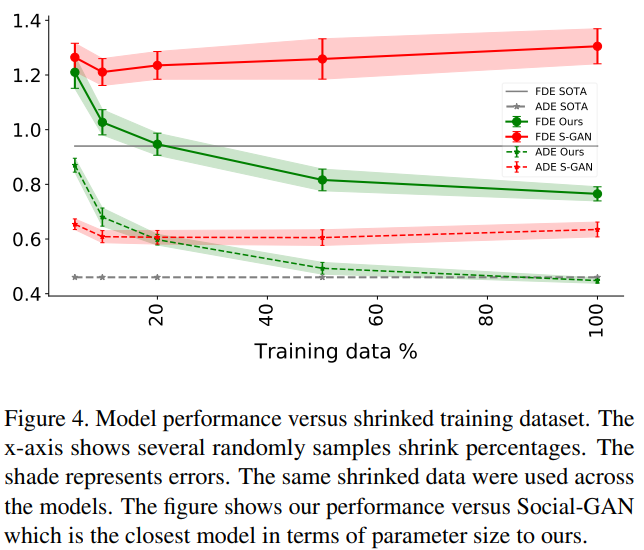
行人轨迹不仅受行人本身影响,还与周围物体的相互作用有关。这篇论文提出了社会时空图卷积神经网络(Social Spatio-Temporal Graph Convolutional Neural Network,Social-STGCNN),将行人与周围物体的交互行为建模为图模型,并通过一个核函数将行人之间的社交互动嵌入邻接矩阵中。实验结果表明,与先前方法相比,Social-STGCNN的最终位移误差较现有技术提高了20%,参数减少了8.5倍,而推理速度提高了48倍。
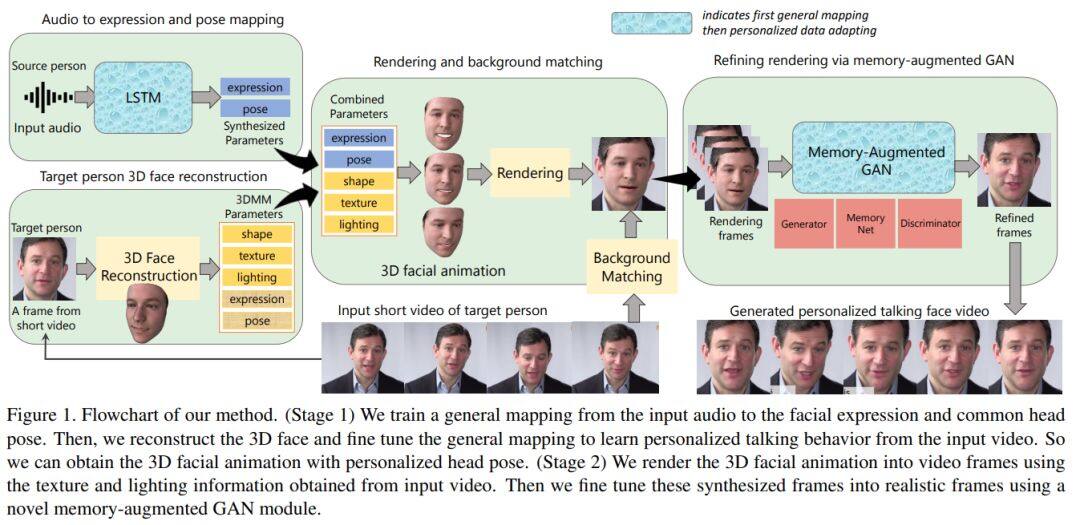
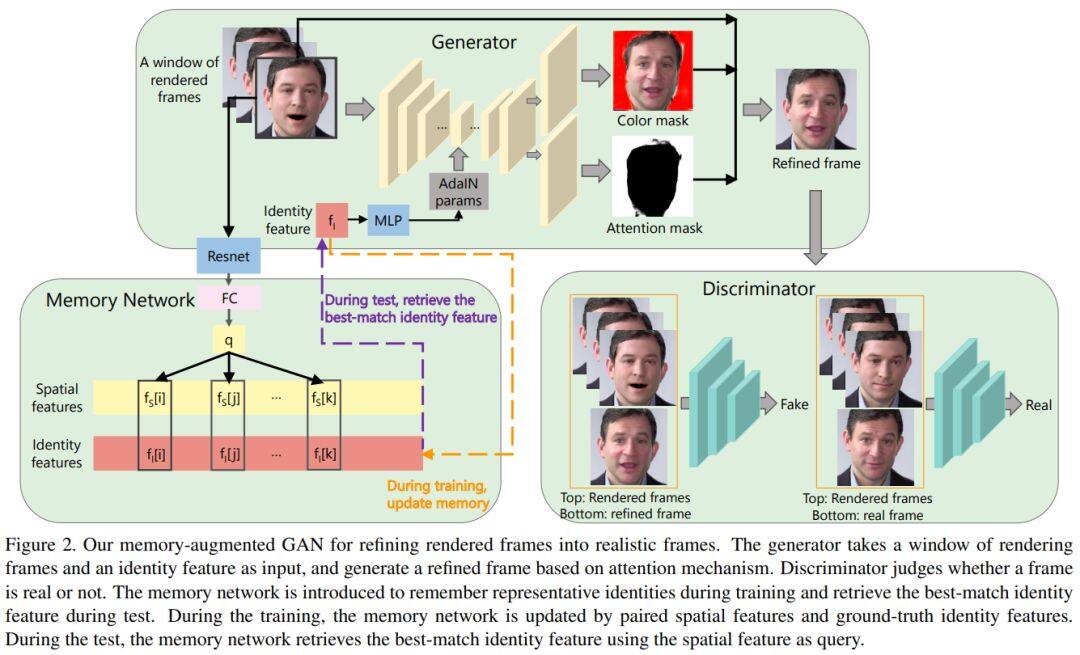
论文名称:Audio-driven Talking Face Video Generation with Natural Head Pose
作者:Ran Yi /Zipeng Ye /Juyong Zhang /Hujun Bao /Yong-Jin Liu
发表时间:2020/2/24
论文链接:https://paper.yanxishe.com/review/12316?from=leiphonecolumn_paperreview0305
推荐原因
现实世界中说话的人脸通常伴随着自然的头部运动,但大多数现有的说话人脸视频生成方法仅考虑具有固定头部姿势的人脸动画。
本文通过提出一个深度神经网络模型来解决此问题,该模型将源人的音频信号A和目标人的非常短的视频V作为输入,并输出合成的高质量说话人脸视频,其具有自然的头部姿势(利用V中的视觉信息),且表情和嘴唇同步(同时考虑A和V)。该项工作最大的挑战是自然的头部姿态包含平面内外的头部旋转,为了解决这个问题,作者重建出3D人脸动画并将其重新渲染为视频序列,为了平滑过渡这些视频的背景图使得结果更加逼真,作者提出了一个新颖的内存增强的GAN模块。
大量实验和用户调研表明,文章方法可以生成高质量(即自然的头部运动,表情和嘴唇的同步)个性化的说话人脸视频,表现优于 state-of-the-art 的方法。
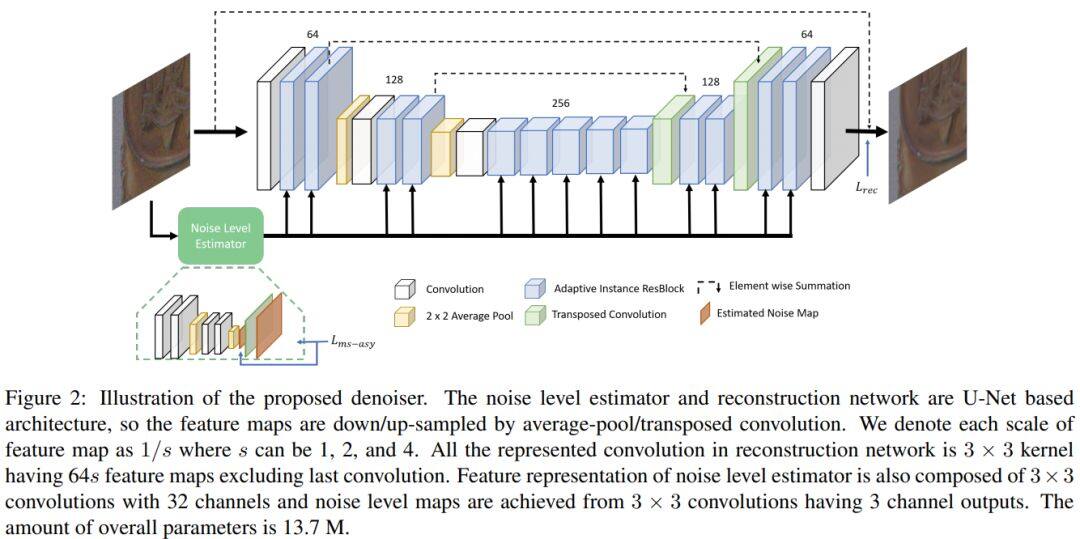
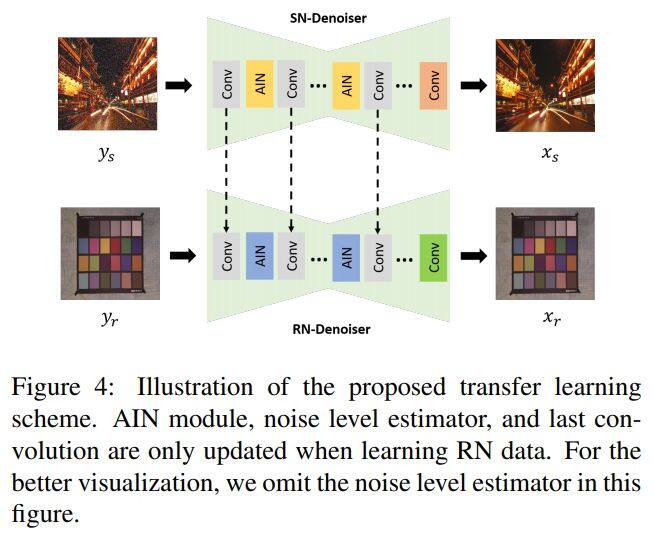
论文名称:Transfer Learning from Synthetic to Real-Noise Denoising with Adaptive Instance Normalization
作者:Kim Yoonsik /Soh Jae Woong /Park Gu Yong /Cho Nam Ik
发表时间:2020/2/26
论文链接:https://paper.yanxishe.com/review/12691?from=leiphonecolumn_paperreview0305
推荐原因
这篇论文被CVPR接收,考虑的是真实噪声的去噪问题。
这篇论文提出了一个广义降噪结构和迁移学习方案来应对各种复杂的实际噪声。这个方案采用自适应实例规范化来构建一个降噪器,可以正规化特征地图,并且防止网络过度拟合训练集。这篇论文还提出了一个迁移学习方法,可以将从合成噪声数据中学习的知识迁移到真实噪声领域。合成噪声降噪器可以从各种合成噪声数据学习一般特征,而真实噪声降噪器可以从中学到真实数据的实时噪声特性。新提出的去噪方法具有很强的泛化能力,在合成噪声上训练的网络能够在Darmstadt Noise Dataset (DND)数据集上取得目前最好的性能结果。
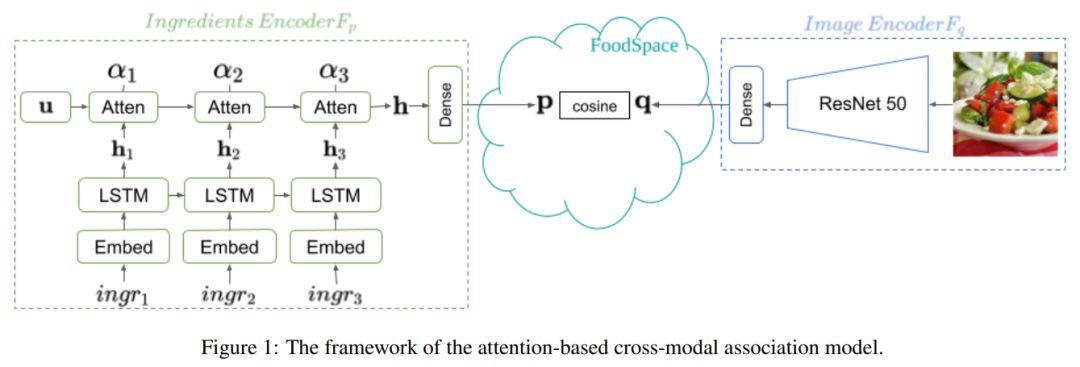
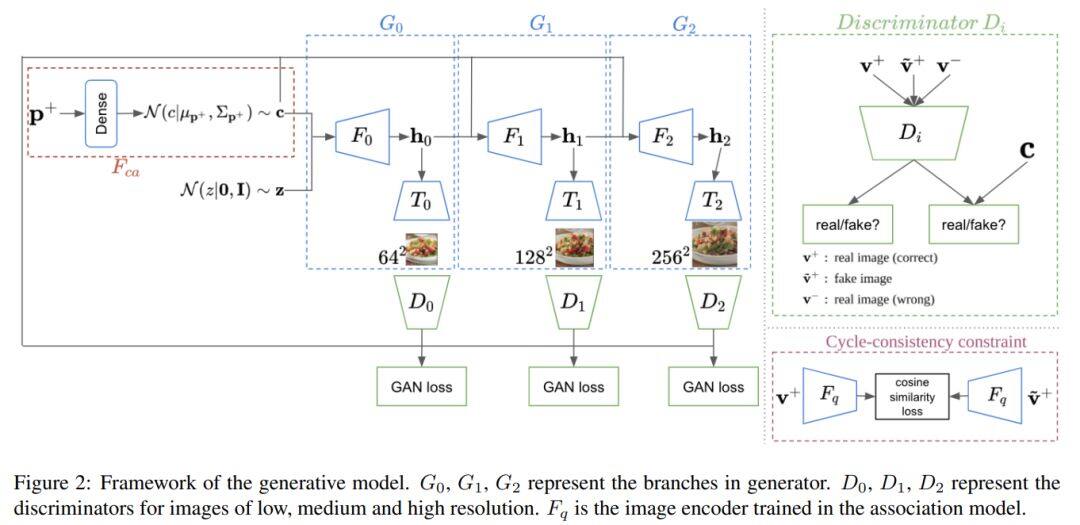
论文名称:CookGAN: Meal Image Synthesis from Ingredients
作者:Han Fangda /Guerrero Ricardo /Pavlovic Vladimir
发表时间:2020/2/25
论文链接:https://paper.yanxishe.com/review/12690?from=leiphonecolumn_paperreview0305
推荐原因
这篇论文发表于WACV 2020,通过食材列表合成逼真的食品图像。
以往利用生成对抗网络进行图像生成的工作主要集中在生成空间紧凑且定义明确的物品上,而食品图像则更加复杂,包含了多种食材成分,其外观和空间品质通过不同的烹饪方式会进一步变化。为了从配料中生成真实的食品图像,这篇论文提出了CookGAN,该模型首先建立一个基于注意力的配料-图像关联模型,然后将其用于调节生成合成食品图像的神经网络。此外,CookGAN添加了周期一致约束以进一步改善图像质量并控制外观。实验表明,CookGAN能生成与成分相对应的食品图像。
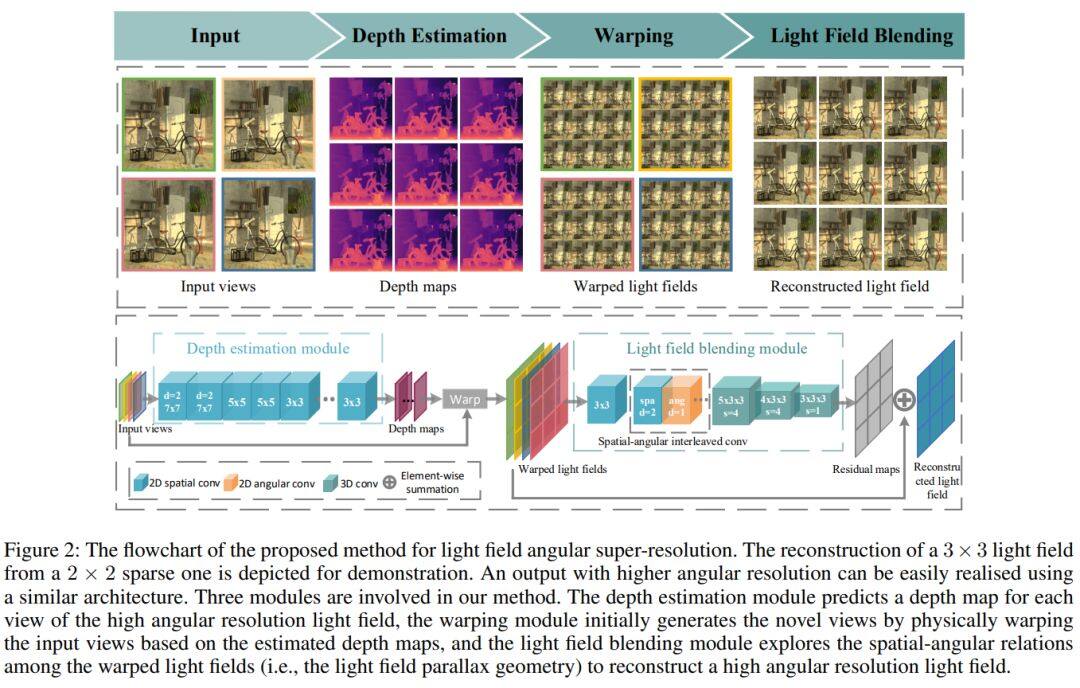
论文名称:Learning Light Field Angular Super-Resolution via a Geometry-Aware Network
作者:Jin Jing /Hou Junhui /Yuan Hui /Kwong Sam
发表时间:2020/2/26
论文链接:https://paper.yanxishe.com/review/12689?from=leiphonecolumn_paperreview0305
推荐原因
这篇论文发表于AAAI 2020,考虑的是光场图像超分辨率的问题。
目前有一些方法用以改善稀疏采样光场的角分辨率,但这些方法主要关注基准较小的光场,例如消费型光场相机。这篇论文提出一种端到端的学习方法,旨在对具有较大基准的稀疏采样光场进行角度超分辨率处理。新方法包括两个可学习模块和一个基于物理的模块:用于显式建模场景几何的深度估计模块,用于新视图合成的基于物理的屈折模块,以及专门设计用于光场重建的光场混合模块。此外,新方法引入一种新损失函数来促进光场视差结构的保存。在包括大基准光场图像在内的各种光场数据集上的实验结果表明,与当前最佳技术相比,这篇论文所提的方法具有明显优势,并且可以更好地保留光场视差结构。

为了更好地服务广大 AI 青年,AI 研习社正式推出全新「论文」版块,希望以论文作为聚合 AI 学生青年的「兴趣点」,通过论文整理推荐、点评解读、代码复现。致力成为国内外前沿研究成果学习讨论和发表的聚集地,也让优秀科研得到更为广泛的传播和认可。
我们希望热爱学术的你,可以加入我们的论文作者团队。
加入论文作者团队你可以获得
1.署着你名字的文章,将你打造成最耀眼的学术明星
2.丰厚的稿酬
3.AI 名企内推、大会门票福利、独家周边纪念品等等等。
加入论文作者团队你需要:
1.将你喜欢的论文推荐给广大的研习社社友
2.撰写论文解读
如果你已经准备好加入 AI 研习社的论文兼职作者团队,可以添加运营小姐姐的微信(ID:julylihuaijiang),备注“论文兼职作者”

雷锋网雷锋网雷锋网
相关文章:
今日 Paper | 点云分类框架;多模式Transformer;神经网络;有序神经元等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

