0
| 本文作者: AI研习社 | 2020-04-08 10:56 |

UnrealText:从虚拟世界合成真实场景文本图像
ScrabbleGAN:半监督变长手写文本生成
ROAM:递归优化跟踪模型
G2L-Net:用于实时6D姿态估计的嵌入矢量特征的全局到局部网络
用于人体姿势估计的多视角图像的可穿戴IMU融合:一种几何方法
论文名称:UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World
作者:Long Shangbang /Yao Cong
发表时间:2020/3/24
论文链接:https://paper.yanxishe.com/review/15414?from=leiphonecolumn_paperreview0408
推荐原因
这篇论文被CVPR 2020接收,提出了一种名为UnrealText的图像合成方法,可以通过3D图形引擎渲染逼真的图像。3D合成引擎通过整体渲染场景和文本来提供逼真外观,并允许访问精确的场景信息。这篇论文通过大量实验验证了所提方法在场景文本检测和识别方面的有效性。这篇论文还会生成多语言版本,以供将来对多语言场景文本检测和识别进行研究。


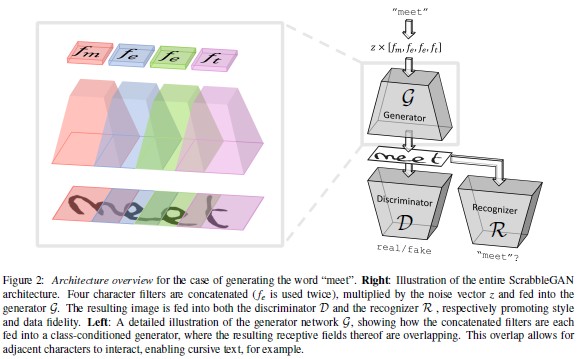
论文名称:ScrabbleGAN: Semi-Supervised Varying Length Handwritten Text Generation
作者:Fogel Sharon /Averbuch-Elor Hadar /Cohen Sarel /Mazor Shai /Litman Roee
发表时间:2020/3/23
论文链接:https://paper.yanxishe.com/review/15413?from=leiphonecolumn_paperreview0408
推荐原因
这篇论文被CVPR 2020接收,考虑的是手写文本生成的问题。
深度学习方法在手写文本识别问题上取得了大幅的性能提高,然而由于手写体的每个人都有独特风格,基于深度学习的训练样本会受到数量的限制。收集数据是一项具有挑战性且代价高昂的任务,而随后的标注任务也非常困难。这篇论文使用半监督方法来减轻数据标注的负担。与完全监督的方法相比,半监督方法除了使用标记数据之外,还使用一些未标记的样本来提高性能,从而能更好地适应测试集中新出现的图像。
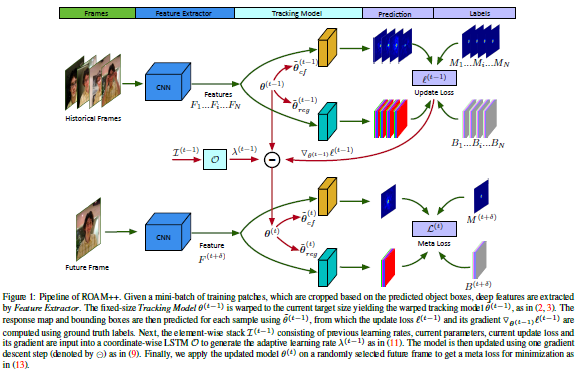
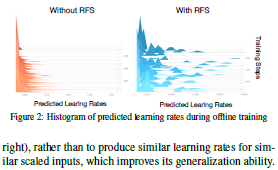
论文名称:ROAM: Recurrently Optimizing Tracking Model
作者:Yang Tianyu /Xu Pengfei /Hu Runbo /Chai Hua /Chan Antoni B.
发表时间:2019/7/28
论文链接:https://paper.yanxishe.com/review/15412?from=leiphonecolumn_paperreview0408
推荐原因
这篇论文被CVPR 2020接收,提出了一个由反应生成和边界框回归组成的追踪模型,其中反应生成部分通过生成一个热图来显示对象出现在不同的位置,边界框回归部分通过回归相对的边界框来定位滑动窗口的位置。为了有效地使模型适应外观变化,这篇论文提出通过离线训练一个递归神经优化器来更新追踪模型,使模型在几个梯度步骤内收敛,提高了更新跟踪模型的收敛速度,同时获得了更好的性能。在OTB, VOT, LaSOT, GOT-10K和TrackingNet基准数据集上评估了新提出的模型、ROAM和ROAM++这两个模型,实验结果表明新提出的方法明显优于最先进的方法。
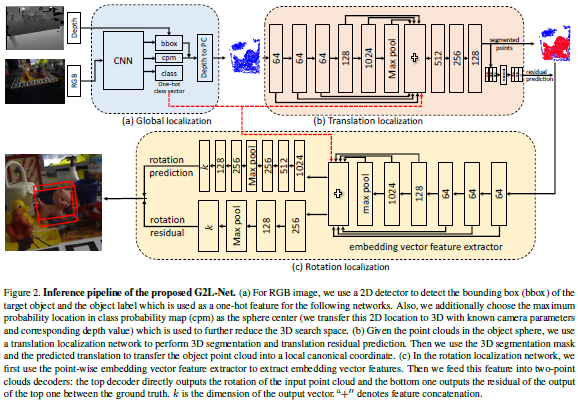
论文名称:G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features
作者:Chen Wei /Jia Xi /Chang Hyung Jin /Duan Jinming /Leonardis Ales
发表时间:2020/3/24
论文链接:https://paper.yanxishe.com/review/15408?from=leiphonecolumn_paperreview0408
推荐原因
这篇论文被CVPR 2020接收,要处理的是姿态估计的问题。
这篇论文提出了一个名为G2L-Net的实时6D目标姿态估计框架,包含三个部分:首先通过二维检测从RGB-D图像中提取粗粒度目标点云;然后将粗粒度目标点云加入到迁移定位网络中进行三维分割和目标迁移预测;最后通过预测得到的分割和平移信息,将细粒度目标点云转化为局部正则坐标,用于训练旋转定位网络来估计初始目标旋转。在第三步中,G2L-Net通过定义逐点嵌入向量特征来捕获视图感知的信息。为了计算出更精确的旋转,G2L-Net还采用旋转残差估计器来估计初始旋转与真实标签之间的残差,从而提高初始姿态估计的性能。在两个基准数据集上的大量实验表明,G2L-Net在精度和速度方面都达到了最新的水平。

论文名称:Fusing Wearable IMUs with Multi-View Images for Human Pose Estimation: A Geometric Approach
作者:Zhang Zhe /Wang Chunyu /Qin Wenhu /Zeng Wenjun
发表时间:2020/3/25
论文链接:https://paper.yanxishe.com/review/15407?from=leiphonecolumn_paperreview0408
推荐原因
这篇论文被CVPR 2020接收,要解决的是3D人体姿势估计的问题。
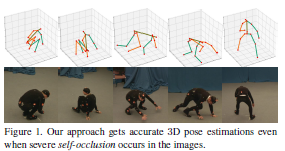
利用可穿戴的惯性测量单元(Inertial measurement unit,IMU),这篇论文提出一种名为定向正则化网络(Orientation Regularized Network,ORN)的几何方法,来增强每对关节的视觉特征。当一个关节被遮挡时,新方法可以显著提高2D姿态估计的准确性。然后,这篇论文通过定向规则化图形结构模型(Orientation Regularized Pictorial Structure Model,ORPSM)将多视图2D姿势提升到3D空间,来最小化3D和2D姿势之间的投影误差,以及3D姿势和IMU方向之间的差异。这种两步的方法明显减少了公开数据集上的误差。


雷锋网雷锋网雷锋网
相关文章:
今日 Paper | COVID-19;深度兴趣网络;COVIDX-NET;场景文本迁移等
雷峰网原创文章,未经授权禁止转载。详情见转载须知。





